

Amint azt már előre jeleztem, ebben a cikkben bemutatom, hogyan lehet a khí-négyzet próbát elvégezni a függetlenség vizsgálatára.
A példa táblázat ugyanaz, mint az előző bejegyzésben (Gyakoribb-e a kék szem a szőkék között? – Khí-négyzet próba a függetlenség vizsgálatára), de most részletesebben kidolgozok majd egy táblát táblázatkezelőben, illetve be fogom mutatni a Minitab megoldását is. A megoldások bemutatásához az előző cikkben használt adattáblák közül az 1908-ban készült tesztet fogom alkalmazni.

Először elkészítettem a teszt riportot táblázatkezelőben. A teszt riport fejlécében nem változott sok minden, csak a teszt típusára vonatkozó mezőket töröltem ki, mert ez esetben ez nem értelmezhető, a fejléc többi része nem változott. Természetesen a nullhipotézis az, hogy a hajszín és a szemszín függetlenek egymástól, az ellenhipotézis pedig az, hogy a két tulajdonság gyakorisága függ egymástól.

Ezután elkészítettem a táblázatokat. Ezeket úgy alakítottam ki, hogy egy 5x5-ös táblát kezelni lehessen a riporttal. Szerintem ez legtöbbször elég, de ha szükséges, akkor a táblázatok kibővíthetők, bár ez esetben ez egy kicsit időigényesebb, mert rengeteg hivatkozást és képletet építettem be a riportba az egyszerűbb kezelhetőség kedvéért. Ha sok ilyen vizsgálatot végzünk, akkor ez az erőfeszítés megtérül: főleg, ha azt is figyelembe vesszük, hogy a képleteket és hivatkozásokat a végén ellenőrizni kell a helyesség szempontjából. Ennek érdekében érdemes teszt adatokat a kezünk ügyében tartani, amelynél ismerjük a részeredményeket és a végeredményt is. Az ilyen teszt adatok alkalmazásával egy új vagy módosított táblázat könnyen ellenőrizhető.
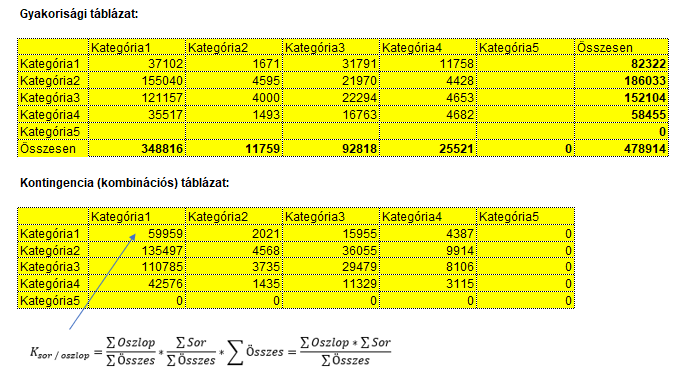
A gyakorisági táblázat tartalmazza a kiinduló adatokat, a kontingencia tábla pedig a kombinált előfordulási gyakoriságokat. Minden egyes cellába beillesztettem az adott cellához tartozó képletet: így, ha megváltoznak a kiinduló adatok, a kontingencia tábla automatikusan újra számolódik. Itt elkövettem egy kis trükköt, a $-jel megfelelő helyekre történő beillesztésével elértem, hogy a megfelelő sorok és oszlopok a képlet másolása esetén is változatlanok maradjanak, így nem kellett minden egyes cellába egyenként beírni a képletet, elég volt egyszer elkészíteni a képletet és aztán csak le kellett másolnom a képletet a táblázat összes többi cellájába, a képlet minden cellában a helyes értéket adja vissza. A képlet a következőképpen néz ki:
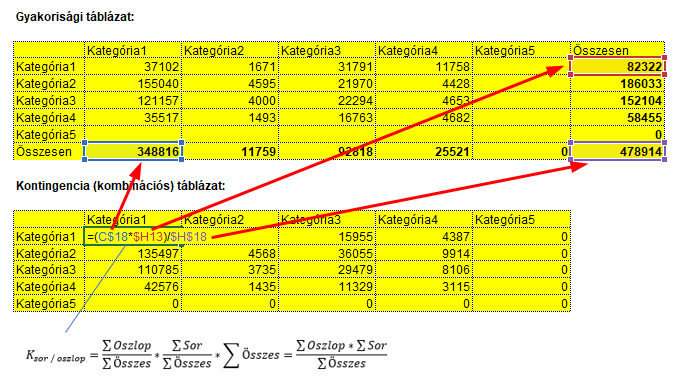
A ’C$18’ cellahivatkozás az oszlopösszegekre mutat. Mivel a ’C’ előtt nincs dollárjel, ha a képletet átmásolom a jobboldali szomszédos mezőbe, akkor a ’C’ betű ’D’-re fog változni. Mivel a ’$18’ elején van egy dollárjel, ezért ha a képletet átmásolom az eggyel alatta lévő mezőbe, akkor a ’18’ nem változik ’19’-re, hanem marad fixen 18. A ’$H13’ hivatkozás hasonlóképpen működik, de ebben az esetben a ’H’ oszlop van fixálva és a sorok száma fog változni a képlet másolása során. A ’$H$18’ cellahivatkozás bármilyen másolás esetén fixen marad, hiszen a teljes végösszeg mindig állandó marad. Természetesen itt is feltüntettem a kontingencia tábla elkészítéséhez használt képletet is. Amikor a kontingencia tábla elkészült, akkor létrehoztam a khí-négyzet változó kiszámításához szükséges összeg táblázatot is:
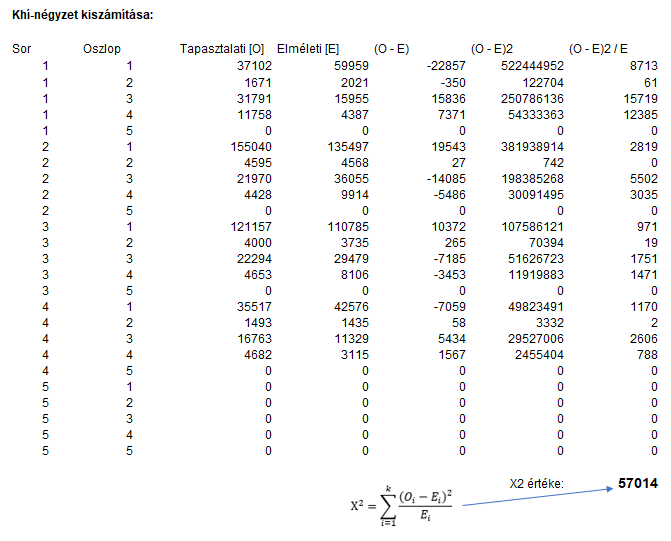
Ebben az esetben nem tartottam meg az eredeti táblázat formátumát, hanem átalakítottam egy lineáris táblázattá. A ’Sor’ és az ’Oszlop’ oszlopokban található sorszámok alapján lehet értelemszerűen beazonosítani az egyes mezőket. Az első sor és első oszlop természetesen a kontingencia tábla bel felső celláját jelöli. A ’Tapasztalati [O]’ és az ’Elméleti [E]’ oszlopokban a gyakorisági és a kontingencia táblázatok megfelelő mezői vannak belinkelve. Az ’(O – E)’ oszlopban van a ’Tapasztalati [O]’ és az ’Elméleti [E]’ oszlopok megfelelő celláinak különbsége szerepel. Az ’(O – E)2’ oszlopban az ’(O – E)’ oszlopban szereplő érték négyzete van (egyszerűen megszoroztam a cella értékét önmagával), majd az ’(O – E)2/E’ oszlopban az előző cella értékét elosztottam az ’Elméleti [E]’ oszlopban szereplő értékkel. Az alábbi képen láthatók a táblázathoz használt képletek:

Végül elérkeztem a khí-négyzet határérték meghatározásához. Ehhez először meg kell adnom a szabadsági fokok számát, majd a KHINÉGYZET.INVERZ() függvény alkalmazásával ki kell számolnom a különféle megbízhatósági szintekhez tartozó khí-négyzet határértékeket. Amint azt az előző bejegyzésben már említettem, a szabadsági fokok számát úgy határozom meg, hogy mind a sorok, mind pedig az oszlopok számából kivonok 1-et, majd a kapott számokat összeszorzom. A KHINÉGYZET.INVERZ() függvény argumentumaiként megadtam a megbízhatósági szinteket tartalmazó cellákat, illetve a szabadsági fok kiszámított értékét tartalmazó cellát.

Az eredmény így a következő lett:
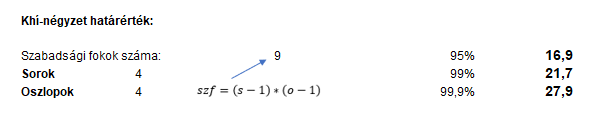
Most már csak a hipotézis vizsgálat következtetését kell megadni. Mivel a táblázatok alapján kiszámított khí-négyzet érték 57 014 lett, a khí-négyzet határérték 95%-os megbízhatósági szinten csak 16,9, de még 99,9%-os megbízhatósági szinten is csak 27,9, ezért egyértelmű, hogy a nullhipotézist elutasítom.

Akkor most nézzük meg, hogyan néz ki ugyanez Minitab-bal. A kiinduló adatokat tartalmazó táblázatot a korábbiakhoz hasonlóan átmásoltam a Minitab táblázatkezelő részébe.
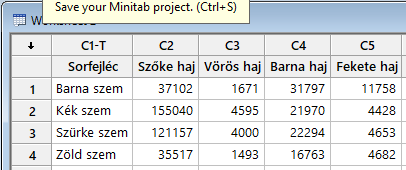
Figyeld meg, hogy a sorfejlécek oszlopába beírtam, hogy „sorfejléc”, egyébként a táblázat ugyanaz, mint a táblázatkezelőben használt táblázat. Erre a teszt beállításainál szükségünk lesz. Ezután a ’Stat” menü ’Tables’ menüjében megnyitom a ’Chi Square test for Association’ menüpontot. Persze miért ne lenne ennek a tesztnek Minitab-ban egy kicsit más a neve, még könnyen megtalálnám! Mindegy, lényeg, hogy megvan.
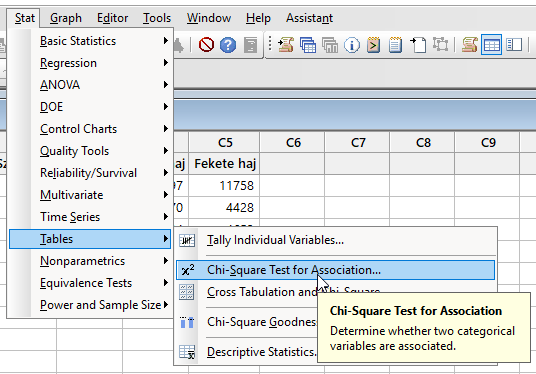
A megjelenő ablakban jobbra fent kiválasztom, hogy az összesített adatokat akarom használni, nem pedig a nyers adatokat, hiszen jelen esetben a nyers adataim nem állnak rendelkezésre.
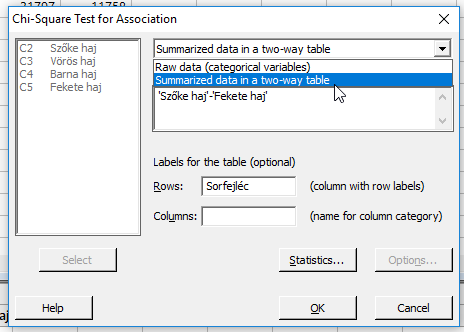
Ezután a ’Columns containing the table’ mezőben megadtam az oszlopokat, amelyek az adatokat tartalmazzák. A ’Sorfejléc’ oszlop neve ekkor nem jelenik meg, mert ez egy szöveges mező, nem számokat tartalmaz. Ezt jelzi az is, hogy a táblázatkezelőben az adattábla felett a ’C1-T’ felirat látható, amelynél a ’T’-betű a text, azaz szöveg szóra utal. A sorok fejlécét a ’Labels for the table (optional)’ felirat alatt a ’Rows’ mezőben tudom megadni. Az oszlopok fejlécét nem kell megadni, azt automatikusan értékeli a program. Ezután márcsak a ’Statistics…’ gomb megnyomásával megjelenő újabb ablakban állítom be, hogy milyen statisztikákat jelenítsen meg a Minitab a riportban.
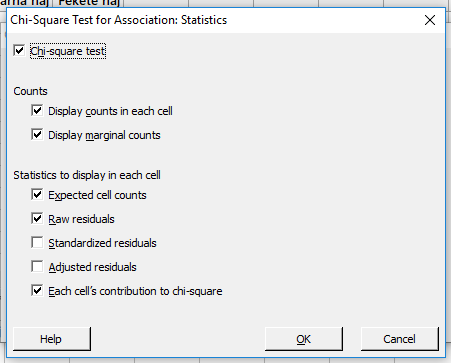
Az eredményhez a korábban táblázatkezelőben kiszámított statisztikákhoz képest csak egy extra értéket kértem, ez a ’Residual’, azaz maradványérték, amely tulajdonképpen a tapasztalati és az elméleti érték különbsége (a bal felső kombináció esetében 37 102 – 59 963 = -22 861). Nyilván minél nagyobb ez az érték, annál jelentősebben járul hozzá az adott kombináció a két kategória változó függőségéhez, hiszen annál nagyobb lesz majd a khí-négyzet értékéhez való hozzájárulása.
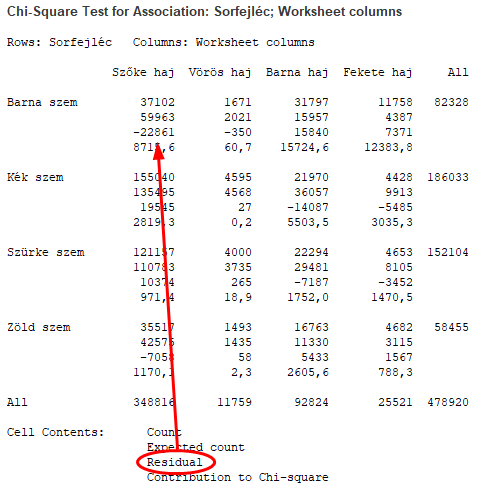
Ezután található a tulajdonképpeni hipotézis vizsgálat, ahol majdnem kijött ugyanaz a khí-négyzet érték (57022 vs. 57014 a táblázatkezelőben), a szabadsági fokok száma ugyanaz (DF = 9), és a P-érték (P-Value) = 0,000, azaz a nullhipotézist elvetjük.





