

Ahogyan azt az előző heti bejegyzésben elemeztük (Ne lógjon ki senki a sorból! - Miért fontos, hogy az adatok normál eloszlásúak-e?), nem érdemes elhanyagolni az adatok ellenőrzését, hogy vajon normál eloszlásúak-e. Ezt viszont nem túl barátságos kézzel elvégezni és az ismert táblázatkezelőknek sincs olyan beépített függvénye, amely segítségével egy mozdulattal vizsgálni tudjuk az adataink eloszlását. Az R alkalmazásával azonban néhány kódsor begépelésével gyorsan és hatékonyan meg tudjuk állapítani, hogy érdemes-e egyáltalán a jól ismert paraméteres teszteket (t-teszt, varianciaanalízis) alkalmazni az adataink esetében.
Már meg sem lepődtem azon, hogy az R alapcsomagjában nem találhatók meg a különféle normalitásvizsgálatok, ehhez is be kell tölteni egy csomagot, ez esetben a ’nortest’ nevűt. Ezt szokásos módon a
library(nortest)
parancs beírásával tudjuk megtenni. Amennyiben ez a csomag nincs telepítve az általunk használt R programhoz, akkor azt vagy az RStudio csomagtelepítője segítségével tudjuk megtenni, vagy pedig az
install.packages(„nortest”)
parancs segítségével. Éles szemű olvasók kiszúrhatták, hogy a ’library’ függvény esetében nem kell idézőjelbe tenni a csomag nevét, míg az ’install.packages’ parancs esetében igen. Erre iagzából nem tudok értelmes magyarázattal szolgálni, sajnos ezt el kell fogadni.
A vonatkozó diagramok megjelenítéséhez egy másik csomagot is javaslok telepíteni és betölteni a vizsgálathoz, ez a ’ggpubr’ csomag. Neki is szép neve van, de csak így elsőre ijesztő. Ez a csomag azoknak készült, akik ki szeretnék használni a ’ggplot2’ csomag előnyeit, de nem akarnak sokat szórakozni a programozásával csak egyszerűen szeretnének egy ilyen vagy olyan diagramot egy rövid parancs begépelésével megjeleníteni. Legnagyobb bánatomra at ’esquisse’ csomag (Diagramkészítés lustáknak – A „Six Sigma in R” sorozat újabb gyöngyszeme) ez esetben nem alkalmazható, mert nem ismeri azokat a diagram típusokat, amire most szükségünk van, szóval a gépelést nem ússzuk meg, csak minimalizáljuk. Azért ismerjük el, hogy inkább szórakoznánk a nagy Star Wars lego készlet megépítésével… Na, mindegy, a pénztelenség nagy úr…
Szóval, ott tartottunk, hogy betöltöttük a két csomagot, amire szükségünk lesz a normalitás elemzéséhez. Kellene még valamiféle adatsor, amit elemezhetünk. Az egyszerűség kedvéért ismét az R beépített adatsorai közül választottam egyet. Ez a ’trees’, amely az R alapszoftverének része, ezért nem szükséges csak az adatok miatt még egy további csomagot betölteni. Az adatsor 31 darab cseresznyefa átmérőjét, magasságát és térfogatát tartalmazza. Az adatsor mezői a következők:
- Girth – a cseresznyefák átmérője hüvelykben megadva (a girth szó körméretet vagy derékbőséget is jelenthet angolul)
- Height – a cseresznyefék magassága hüvelykben megadva
- Volume – a cseresznyefák térfogata köblábban megadva
Ahogy azt fentebb említettem, az adatsor betöltéséhez nincs szükség különösebb varázslatra, az egyetlen dolog, amit megtettem, hogy az adatsort egy ’t’ nevű változóval hivatkozom meg a továbbiakban, amelynek célja csak annyi, hogy kevesebbet kelljen gépelni.
t <- trees
Ekkor az RStudio változókat tartalmazó ablakában (amely a képernyőn látható jobb felső ablak) megjelenik a ’t’ változó, amely 3 változót (variables) és 31 megfigyelést (observation) tartalmaz. A táblázatot a
View(t)
paranccsal vagy az R változóablakában a ’t’ változóhoz tartozó kis táblázat ikon segítségével is meg tudjuk jeleníteni. Vigyázz, a ’View()’ első betűje nagybetű.
Kezdjük az adatok vizsgálatát azok vizuális elemzésével. Például a ’Height’ nevű változó adatai a következőképpen néznek ki.
gghistogram(t$Height, bins = 6)
ggqqplot(t$Height)
A ’gghistogram()’ függvény esetében a ’bins = 6’ paraméter azt jelenti, hogy az adatokat sorolja 6 különböző intervallumba. Ha ezt nem adjuk meg, akkor az R alapból 30 intervallumot alkalmaz, de ez túl sok. A hisztogramról korábban már leírtam (Hisztogram - amiről már sok szó esett korábban...), hogy körülbelül annyi intervallumra érdemes felosztani, mint az adatok számának négyzetgyöke. Ez esetben 31 adatunk van, ennek a négyzetgyöke 5,56, ezért állítottam be 6 intervallumot.
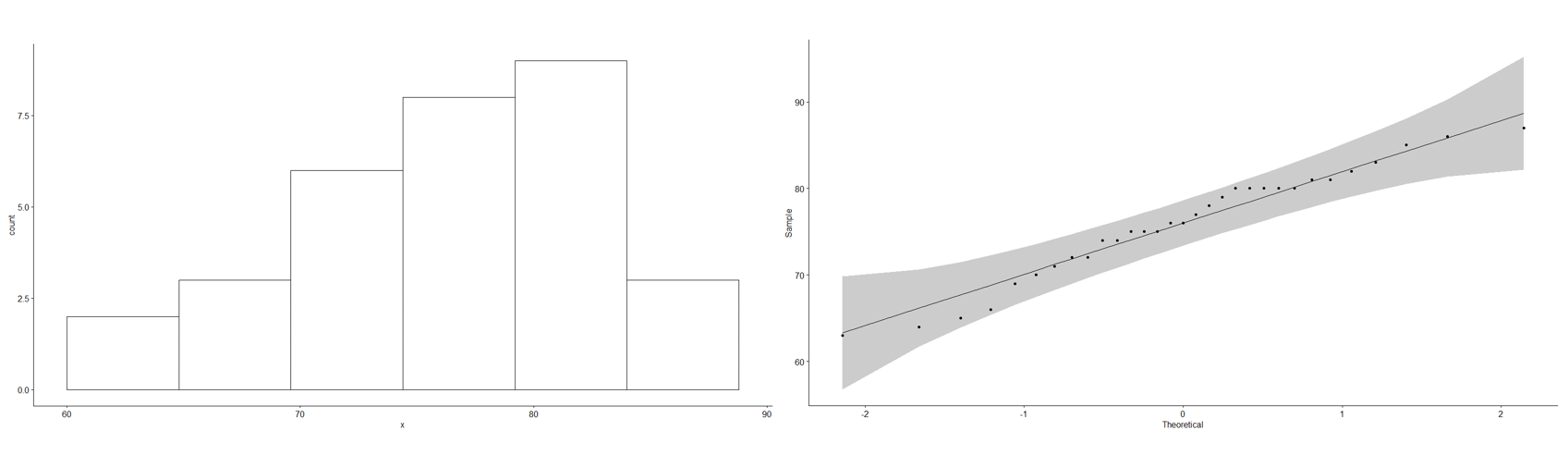
A bal oldalon található hisztogram sajnos így nem sokat mond, mert túl kevés az adat ahhoz, hogy az eloszlást meg lehessen ítélni ez alapján. Olyan, mintha az adatsor aszimmetrikus lenne, de konkrét döntést nem mernék hozni ez alapján. A mellette lévő úgynevezett Q-Q plot (lásd az előző cikket, meghivatkozva fent…) már többet mond. Ha megnézzük, a pontok körülbelül az egyenes körül szóródnak, illetve minden pont benne van a szürke sávval kijelölt megbízhatósági tartományban.
Most nézzük meg ugyanezt a Volume változóra is.
gghistogram(t$Volume, bins = 6)
ggqqplot(t$Volume)

Egyből látszik, hogy itt siralmasabb a helyzet, mert a hisztogram is sokkal inkább eltér a megszokott normál eloszlás szimmetrikus képétől, illetve a Q-Q plot-on is sokkal messzebb vannak a pontok az egyenestől és itt vannak a szürke zónán kívüli pontok is.
Akkor most nézzük meg, mit mutatnak a normalitási tesztek.
lillie.test(t$Height)
shapiro.test(t$Height)
ad.test(t$Height)
A ’lillie.test()’ – szigorúan két l-lel a szó közepén – a lilliefors teszt eredménye jelenik meg, amelyről korábban megtudtuk, hogy a Kolmogorov-Smirnov teszt kicsit feljavított változata. A ’shapiro.test()’ természetesen a Shapiro-Wilk tesztet, az ’ad.test()’ parancs pedig az Anderson-Darling tesztet takarja. Ha lefuttatjuk a három parancsot a ’Height’ változóra, akkor a következőket kapjuk:
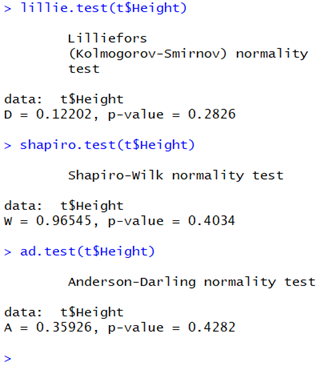
Igazából mindhárom esetben a ’p-value’ (A titokzatos P színre lép – Mi az a P-Value?) értékét érdemes nézni, amely mindhárom esetben nagyobb, mint 0,05, ami azt jelenti, hogy a nullhipotézist, mely szerint az adatok normál eloszlásúak NEM tudjuk elvetni. Ezt úgy lehet lefordítani, hogy NEM IGAZOLHATÓ, hogy az adatsor szignifikánsan eltérne a normál eloszlástól. Vagyis azt nem állíthatjuk, hogy az adatsor normál eloszlású, csak azt, hogy nem igazolható, hogy lényegesen eltérne a normál eloszlástól!
És mi a helyzet a ’Volume’ változóval?
lillie.test(t$Volume)
shapiro.test(t$Volume)
ad.test(t$Volume)
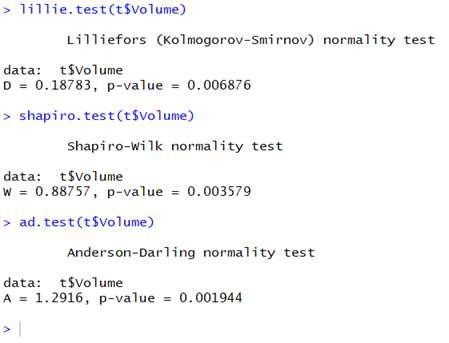
A ’Volume’ változó esetében a p-értékek messze kisebbek, mint a kiválasztott 0,05 megbízhatósági határérték, vagyis ez esetben biztosan állíthatjuk, hogy a ’Volume’ mezőben lévő adatok NEM normál eloszlásúak.



