A 
A konfekció ruházat méretezésének kialakulása nagyon jó példája volt a tanulási folyamat részét képező modellalkotásnak. A ruhakészítők felismerték a lehetőséget abban, hogy noha minden ember testalkata más és más, néhány jellemző tulajdonság alapján bizonyos határok között mégiscsak csoportokba sorolhatók, ezáltal ugyanaz a méretű ruha nemcsak egy emberre lesz jó, hanem nagyon másikra is. Így 5-6 különböző ruhaméret gyártásával akár több ezer vagy tízezer vásárló részére is lehet rájuk passzoló ruhadarabokat varrni.
A testalkati modellek megalkotásához nagyszámú megfigyelésre volt szükség. A 15 000 hölgy testének részletes vizsgálata alapján találtak jellegzetes mintázatokat, és ezeknek az adatoknak a felhasználásával modelleket alkottak. és ezeknek az adatoknak a felhasználásával modelleket alkottak. Az emberi szervezet tulajdonságai miatt a magas, karcsú vagy az alacsony, molett testalkatú hölgyek különféle testméretei szinte célzottan közelítenek bizonyos átlagértékek felé. Szinte biztos, hogy a hölgyek nagyon kis százalékának egyeznek meg a méretei pontosan ezekkel a bizonyos értékekkel, sőt talán egyetlen olyan hölgy sem létezik a földön, akinek az alakja pontosan megegyezik valamelyik ilyen idealizált testmodellel. De ez nem is fontos. Ha a hölgyek különféle méretei bizonyos határok között megközelítik ezeket a bizonyos értékeket, az már elég ahhoz, hogy passzoljon rájuk a ruhadarab. Ez a fajta általánosítás nagyon hasznos a számunkra, mert lehetőséget teremt az érzékelésen és tapasztalatszerzésen alapuló ismeretszerzésre, ezek az ismeretek segítenek minket a döntéshozatalban bizonyos szituációkban (például, hogy melyik méretű ruha fog a legjobban állni rajtunk).
Amikor elemezzük a megfigyeléseinket és az ezek során megszerzett adatokat, legtöbbször két fő kérdés merül fel:
- Mi az a jellemző középérték, amely felé az adatok szisztematikusan közelednek és ha van ilyen, akkor hogyan határozzuk meg?
- Mekkora az adatok szóródása a középérték körül, azaz mennyire jellemző a középérték az adathalmazra?
Lássuk be, hiába tudunk meghatározni akármilyen középértéket, amelyről azt állítjuk, hogy az jellemzi az adatokat: ha az adatok nem közelítenek elég szisztematikusan ehhez az értékhez, akkor nehezen hihető, hogy ez az érték jól használható az adathalmaz jellemzésére. Ebből a szempontból a középérték kifejezés talán nem is annyira szerencsés. Az angol „Central tendency measures” kifejezés, ami talán a középpont felé való törekvés mérőszámaiként fordítható le, sokkal jellemzőbb meghatározása az adathalmaz ilyen tulajdonságainak, mint az általam használt „középérték” fogalom.
Egy adathalmaz középértékét sokféle módszerrel meg lehet határozni. Az, hogy melyiket választjuk, leginkább attól függ, hogy melyik lesz az a bizonyos középérték, amely felé a legtöbb adat közelít vagy amelyhez a leginkább közel vannak az adatok. Sajnos ennek a kiválasztása sem mindig egyértelmű.
Darrell Huff amerikai író és újságíró 1954-ben megjelent Hogyan hazudjunk statisztikával (Darrel Huff: How To Lie With Statistics, New York 1954), című könyvében szemléletesen mutatta be, hogy a nagyvállalatok jelentéseikben miért használják inkább a fizetések átlagát, mint a mediánt és a móduszt.

Az átlag (a képen arithmetic average) jelentését talán kevésbé kell magyarázni, mert ez valahogy jobban megragadt a tanulmányaink során és gyakrabban is használjuk. Összeadjuk az adathalmaz elemeit és az összeget elosztjuk az elemek számával.
A középérték egy másik mérőszáma a medián (median), amely a nagyság szerint sorba rendezett elemek közül a középső elem értéke, illetve páros számú elem esetén a két középső elem átlaga.
A harmadik mérőszám a módusz (mode), amely az az érték, amellyel az adathalmaz legtöbb eleme megegyezik, vagy amelyhez a legtöbb elem közelít.
Nyilván létezik még jónéhány más mérőszám is a középérték jellemzésére, de ezt a hármat alkalmazzuk leggyakrabban. A fenti példa is mutatja, nem lehet kijelenteni, hogy ez a mérőszám jobb, mint az a másik mérőszám, de az a harmadik a legjobb mind közül. Azt, hogy egy adott helyzetben melyik mérőszám adja a legjobb közelítést a valósághoz, sajnos az adathalmaz elemeinek gyakorisági eloszlása dönti el. Ez viszont egy összetettebb téma, amellyel később még foglalkozni fogunk.
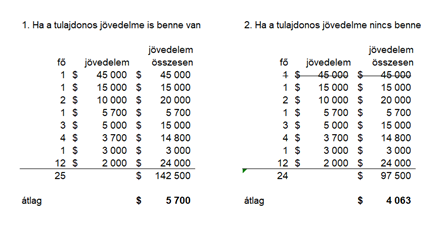
Visszatérve a képre. A könyv szerzője szerint a vállalatok jobban szeretik az átlagfizetéseket használni a jelentéseikben, hogy pozitívabb színben tüntethessék fel magukat, miszerint náluk sokkal többet keresnek az alkalmazottak. Igen ám, de a legtöbb esetben néhány alkalmazott jelentősen többet keres a nagyátlagnál és ez felfelé húzza az átlagot (sajnos az átlag érzékeny a kieső értékekre, amelyek távol esnek az átlagtól - lásd az "Adathalmazok középértékének mérőszámai" című videót). Ez persze szépen mutat a riportokban, viszont igencsak messze áll a valóságtól. A medián talán egy fokkal jobb, hiszen részlegesen kiegyenlíti a vezetői fizetések miatti torzítást. Ebben az esetben a módusz adja az adathalmazra leginkább jellemző értéket, hiszen az alkalmazottak legnagyobb része körülbelül ennyit keres. Ez viszont lefelé torzít, nem tükrözi eléggé az irodai és a középvezetői réteg magasabb jövedelmének hatását. Összegezve azt lehet mondani, hogy egy ilyen girbe-gurba eloszlású adathalmaz esetében a három közül egyik mérőszám sem jellemzi eléggé azt, hogy az adatok milyen értékhez közelítenek.
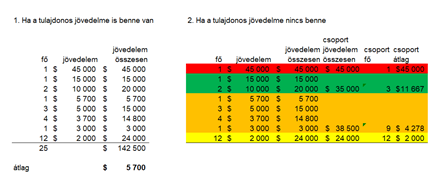
De akkor mi lehet a megoldás? Elképzelhető mondjuk az, hogy a legmagasabb jövedelmű vezetőket (például a felső 5%-ot) kivesszük a vizsgálatból, mert ők általában egyébként sem hétköznapi dolgozói a vállalatnak. Ebben a példában a tulajdonos – aki nem egyszerű alkalmazottja a cégnek – jövedelmét kivéve és így az átlagot jelentősen csökkentve sokkal reálisabb képet kapunk a fizetésekről.
Egy másik lehetőség az, ha szétválasztjuk a különböző dolgozói csoportokat. Így nem egy átlagot kapunk, hanem hármat vagy négyet, de ez megint csak pontosítja a jövedelmek valóságos mértékéről alkotott képet. Az igaz viszont, hogy bonyolultabbá teszi a jövedelmi viszonyok megértését, hiszen ha külön kezeljük a fizikai munkások, az irodai dolgozók, a vezetők jövedelmét, akkor mindenki megtudhatja a saját érdeklődésének megfelelő fizetési kategória átlagos jövedelmi szintjét - ha ez egyébként érdeke a tulajdonosnak.
Ezek szerint többféle lehetőségünk is van az adatok értelmezésére és csak rajtunk múlik, hogy mennyire egyszerűsítjük le a tényeket vagy esetleg mennyire torzítjuk el valóságot pillanatnyi érdekeinknek megfelelően.
A középérték mérőszámok jelentőségének megértésében segít az alábbi videó is (A videó a képre kattintva indul el):