

A főkomponens elemzés (Principal Component Analysis) röviden összefoglalva egy árnyjáték, ahol egy bonyolult térbeli alakzat árnyképét úgy próbáljuk rávetíteni egy síkfelületre, hogy közben az alakzat jellegzetes tulajdonságaiból minél kevesebbet veszítsünk el. Csak éppen ez a térbeli alakzat nem feltétlenül háromdimenziós. Lehet, hogy négy-, vagy ötdimenziós, vagy még több…
A módszer matematikai megvalósítása tele van mátrixműveletekkel. Ennek oka, hogy a módszer alapja a lineáris algebra világába vezet és igényli néhány elvont fogalom megértését is, úgymint az sajátvektorok (eigenvectors) és a sajátértékek (eigenvalues). Akit érdekel annak javaslom, hogy keresse fel Sajó Zsolt Attila oldalát, aki bevezet a főkomponens elemzés elméleti matematikai hátterébe.
https://sajozsattila.home.blog/2021/08/02/fokomponens-analizis-2/
A példa kedvéért most az atlétika világába fogunk kirándulni egyet, ezen belül is a tízpróbázók (decathlon) teljesítményét fogjuk elemezni. Adott egy adatsor, amelyben tízpróba versenyzők eredményei találhatók, konkrétan az, hogy mennyi volt az időeredményük 100 és 400 méteres síkfutásban, 110 méteres gátfutásban vagy milyen messzire sikerült elhajítaniuk a gerelyt vagy a diszkoszt. Az eredmények 2004-ből származnak, két különböző versenyről. Az egyik az egyébként minden évben Franciaországban megrendezett DECASTAR verseny, a másik pedig a 2004-es Athéni Olimpiai Játékok. Az adatsorban vannak olyan versenyzők, akik mindkét versenyen részt vettek és olyanok is, akik csak az egyiken. Az adatsor ezen kívül még tartalmazza a sportolók versenyen elért helyezéseit és a megszerzett pontszámait is.
Mi is az elemzés tárgya ebben az esetben. A listában szereplő sportolók képességei nem egyformák, és a sportág szabályai szerint a győzelemhez szükséges pontok is sokféle módon szerezhetők meg. Minden sporttoló a saját adottságainak megfelelő taktikát választ a legjobb eredmény elérése érdekében.
Vajon lehetséges-e valamilyen módon megalkotni egy versenyző profilját kizárólag az eredményei alapján? Másképpen fogalmazva lehetséges-e megjósolni egy versenyző jövőbeni pontszámait a hozzá hasonló profilú versenyzők eredményei alapján?
Elvileg minden lehetséges, de vajon mit láthatunk konkrétan az adatokból? Merthogy a 10 különböző sportág azért egy komoly kihívás, ha át akarjuk látni ezt a kusza és bonyolult rendszert, ahogy az látszik is az alábbi diagramon. Bizonyos szabályszerűségek persze felfedezhetők a sportolóknak az egyes sportágakban elért eredményei között, de az összképről vajmi kevés fogalmat alkothatunk pusztán ennyi elemzés alapján.
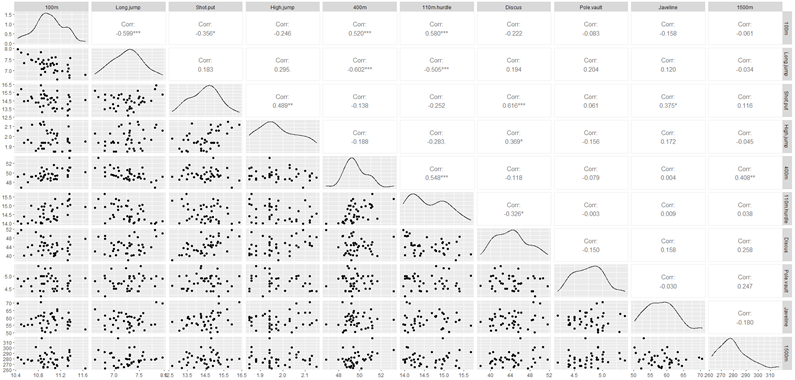
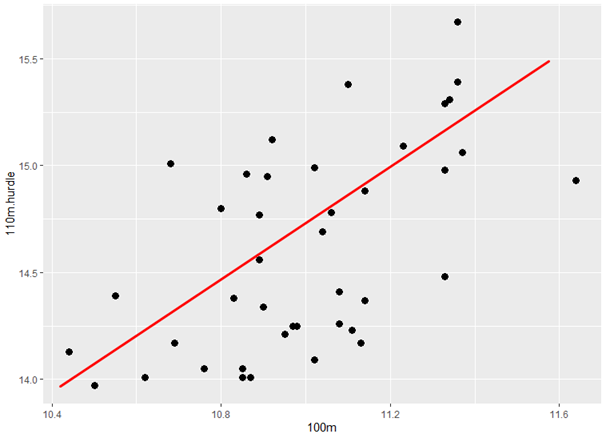
A diagramon megfigyelhető, hogy vannak olyan sportágak, amelyeknek az eredményei szorosabb összefüggést mutatnak. Például ilyenek a rövidtávfutó számok. A 100 méteres síkfutás (100m) és a 110 gát (110m hurdle) eredményei között egészen szoros pozitív korreláció van (+0,58), hiszen aki a 100m-en gyorsabb, az valószínűleg a 110 gátfutást is gyorsabban fogja teljesíteni. Hasonló összefüggés fedezhető fel a súlylökés (Shot put) és a diszkoszvetés (Discuss) között (+0,616), vagyis aki erősebb, az a súlygolyót is messzebbre löki és a diszkoszt és messzebbre hajítja el. Ami viszont akár meglepő is lehet, hogy például a magasugrás (High jump) és a rúdugrás (Pole vault) eredmények között csak -0,156 a korrelációs együttható értéke, vagyis a két sportág eredményei nemigen határozzák meg egymást.
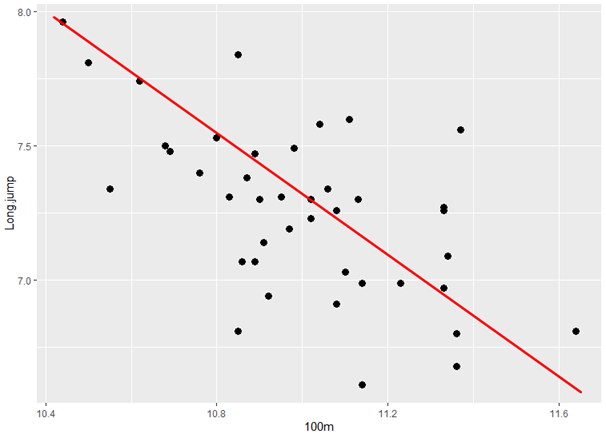
Érdekes lehet, hogy amikor a 100 méteres síkfutás és mondjuk a távolugrás kapcsolatát vizsgáljuk, akkor viszont egy fordított korrelációt fogunk tapasztalni, hiszen a 100 méter esetében minél kisebb az időeredmény, annál jobb. A távolugrás esetében viszont a nagyobb távolság jelent jobb eredményt.
Szóval egy ilyen komplex diagramból jónéhány megfigyelést tudunk tenni, de az egyes sportágakat igazából csak párosával tudjuk vizsgálni. Tudnánk persze még hármasával is vizsgálni a sportágakat, de még ez is messze van attól. hogy feltérképezük az adatsorban található mélyebb összefüggéseket.
Jó lenne valahogyan leegyszerűsíteni ezt az összképet. A 10 darab sportág túl sok információt és túl bonyolult összefüggéseket jelent, amelyeket nagyon nehezen tudunk észszerű módon feldolgozni. Ahhoz, hogy az adatokat ábrázolni tudjuk, le kellene csökkentenünk a vizsgált tényezők számát kettőre vagy háromra, mert ennyit még meg tudunk jeleníteni emészthető formában síkban vagy térben. Azonban
a tényezők számát valahogy úgy kellene csökkentenünk, hogy közben a lehető legkevesebb információt veszítsük el.
Vagyis az nem az optimális megoldás, ha a 10 sportágból kiválasztjuk a kettő vagy három legfontosabbat, majd ezek felhasználásával elemezzük a sportolók teljesítményét. A hiányzó sportágak információinak elvesztése túl erősen torzítaná az eredményeket. Az a célunk, hogy a 10-féle sport által kijelölt 10-dimenziós adathalmazt úgy csökkentsük le kettőre vagy háromra, hogy mind a tíz sportág által szolgáltatott információk benne maradjanak. Sajnos azonban ez még nem elég a boldogságunkhoz, mert amikor „ránézünk” erre a 10-dimenziós adathalmazra, akkor nem mindegy, hogy melyik irányból nézünk rá. Egy hétköznapi tárgy szemrevételezésekor sem mindegy, hogy melyik irányból szemléljük. Erre szemléletes példa az árnyjáték, amikor a kezünkből képzett háromdimenziós alakzatokat a fény segítségével oly módon vetítjük a falra vagy egy vászonra, hogy ott egy a nézők számára felismerhető alakzat jelenjen meg.

Ahogy az árnyjáték esetében sem mindegy, hogy a kezünkhöz képest merről érkezik a fény, a vizsgált n-dimenziós adathalmazunk esetében sem mindegy, hogy az n-dimenziós tér melyik irányából vetítjük a ponthalmaz képét a két- vagy esetleg háromdimenziós felületre. Az alábbi képen látható példa illusztrálja a fenti jelenséget, ahol a hulladékból előállított szobrot különböző helyekről megvilágítva különböző alakú árnyékokat kapunk.

És itt egy érdekes kérdéssé válik az, hogy mi hordozza az adatok között a számunkra fontos információkat. Az ehhez hasonló esetekben a számunkra értékes információt az adatok közötti variancia, az átlagostól való eltérések jelentik. Tehát az adatoknak egy olyan szűkítését szeretnénk elvégezni, amely a teljes variancia minél nagyobb százalékát tartalmazza.
A lényeg, hogy az adatokat a sportágak helyett úgynevezett főkomponensek mentén fogjuk vizsgálni. Ezek a főkomponensek olyan irányok a "10-dimenziós térben”, amelyek megadják, hogy az adatoknak melyik irányban a legnagyobb a varianciája. Vagyis az első főkomponens – amelyet általában PC1-gyel szoktak jelölni – azt az irányt adja meg, amelyben a legnagyobb a vizsgált adatok varianciája. A második főkomponens (PC2), a PC1-re merőleges irány, amerre az adatok varianciája a második legnagyobb, és így tovább. Ennek módját a források között található StatQuest videó nagyon szemléletesen mutatja be.
A fentiek alapján a főkomponens elemzésnek két feladata van:
- Meghatározza a főkomponenseket, amelyek irányában a pontok varianciájának legnagyobb része található, és
- Megadja azt az irányt az n-dimenziós térben, amerre a ponthalmazból a legtöbb információ „látható” a két-, vagy háromdimenziós térben.
Mivel egyrészt remek anyagok állnak rendelkezésre a módszer hátteréről, másrészt ingyenes szoftverek segítségével el lehet végezni az elemzéseket anélkül, hogy olyan nagyon sokat kellene számolgatni, ezért inkább most az eredmények értelmezésére fordítanám az energiáimat.
Nos, a vizsgálatunk eredményei a következőképpen néznek ki. Először is, mivel 10 sportágunk van, ezért kapunk eredményként 10 főkomponenst, amelyek az egyes sportágak kombinációiként jönnek létre:

Mit jelentenek ezek a számok? Kiválasztok egy sportolót – legyen mondjuk Serble – akinek az eredményei a következők:

Ezekből ki lehet számolni az egyes főkomponensek értékét úgy, hogy a fenti eredmények normalizált értékeit megszorzom a PC1-hez (PC2-höz, PC3-hoz, stb.) tartozó súlyozási értékekkel, majd ezeket összeadom. Ezt persze a valóságban nem kell elvégeznem, mert a szoftverek általában ezt is elvégzik helyettünk, és az eredményeket ábrázolhatjuk egy olyan diagramon, amelynek x-tengelyén a PC1, y-tengelyén pedig a PC2 helyezkedik el.
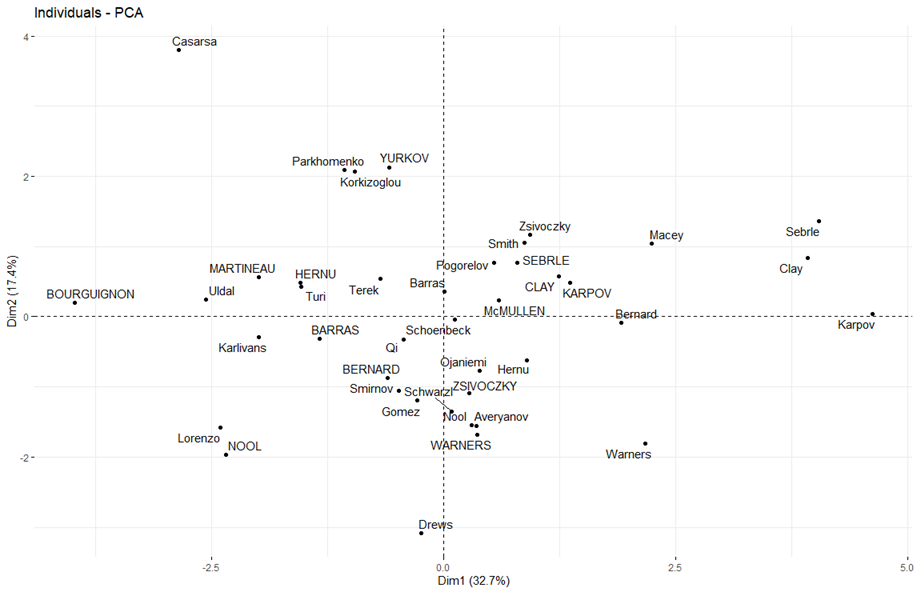
A főkomponensekhez tartozó sportág súlyozó értékek valamilyen szinten arról is tájékoztatást adnak, hogy a főkomponenseken belül melyik sportágnak van nagyobb és melyiknek kisebb súlya. Például a PC1 esetében nagy súllyal esik latba a 100 méteres síkfutás (-0,7747), a 110 m gátfutás (-0,7462), a távolugrás (0,7418) és a 400 m síkfutás (-0,6796). Vagyis akinek magas PC1 értékek jönnek ki, azok erősek a rövidtávfutó számokban, a távol-, és magasugrásban, esetleg súlylökésben, de nem annyira erősek a rúdugrásban vagy az 1500 méteres síkfutásban. Úgy képzelem, hogy neki inkább ezek a számok az erősségei.
A PC2 főkomponensben egyértelműen a diszkoszvetés (0,6063), a súlylökés (0,5983) és a 400 m síkfutás (0,5694) szerepel nagyobb súllyal, míg a 100 m síkfutás és a 110 gát eredményei kevésbé számítanak. Vagyis a vízszintes tengely inkább a gyorsaságról, a függőleges pedig inkább az erőről szól. Például a bal felső sarokban szereplő Casarsa az eredményei alapján inkább erős, mint gyors, a bal alsó negyedben található Lorenzo vagy Nool valószínűleg se nem igazán gyors, se nem igazán erős. Persze ez itt most nem abszolút értelemben, hanem az adattáblában felsorolt versenyzők között értendő.
Ezt igazolja az is, hogy Roman Serble mindkét versenyen első helyezést ért el, Paolo Casarsa csak az olimpián szerepelt, de ott 28. lett, míg Erki Nool a Decastar-on a 12., Santiago Lorenzo pedig az olimpián a 24. helyet szerezte meg.
Vajon van-e hatása a versenyeknek? Az olimpián vajon jobban teljesítenek a versenyzők, mint a Decastar versenyen?
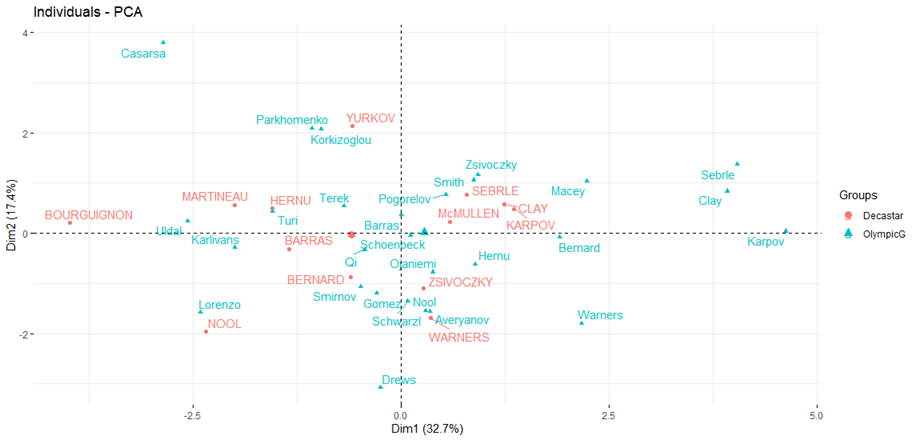
Nos két dolog miatt is azt mondhatjuk, hogy van különbség a két verseny között, noha az eltérés elsőre talán nem szembetűnő:
- Egyrészt a versenyzők az olimpián elért eredményekkel inkább az x-tengely jobb oldalán, a Decastar versenyen.
- Másrészt vannak olyan versenyzők, akik mindkét versenyen részt vettek, de az olimpián elért eredményeik inkább jobbra helyezkednek el, mint a Decastar versenyen elért eredmények (A csupa nagybetűs nevek a Decastar, a kisbetűvel írt nevek az olimpián indult versenyzők neveit mutatják).
Ha még ennél is látványosabban szeretnénk megmutatni a két verseny közötti különbséget, akkor ellipszisekbe is foglalhatjuk őket:

Ha mondjuk csak a top 10 versenyzőre vagyunk kíváncsiak. akiknek a legnagyobb hatása van a varianciára, azt is ábrázolhatjuk:
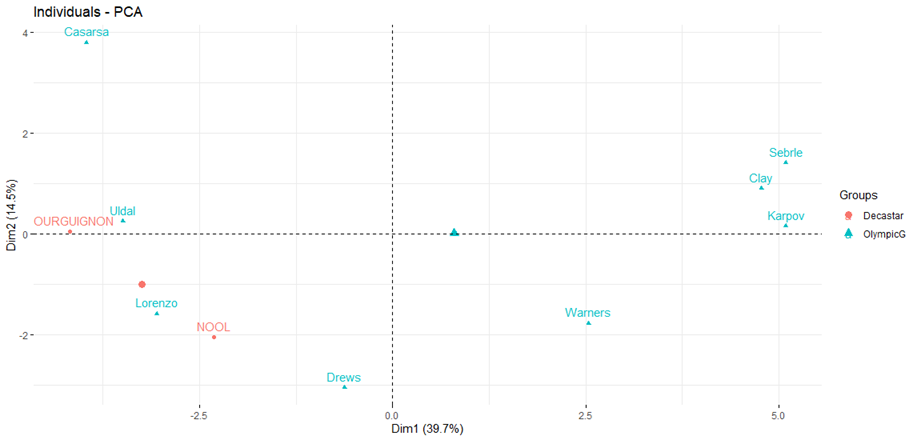
Rendben, de itt még nem szűkítettük le a főkomponensek számát, vagyis a célunkat még nem értük el. De vajon mekkora a hatása az egyes főkomponenseknek a teljes varianciára nézve? Melyik főkomponens a teljes varianciának mekkora részéért felel? Erre szolgál az úgynevezett Scree-plot, amely egyfajta pareto-diagramon ábrázolja a főkomponenseket.
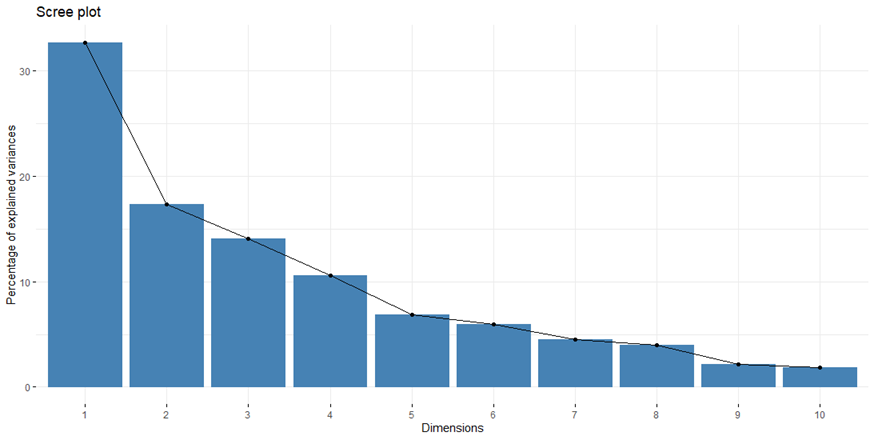
Az x-tengelyen az egyes főkomponensek szerepelnek 1-től 10-ig, a függőleges tengelyen pedig ezek százalékos részesedése szerepel a teljes varianciából. Vagyis a PC1 több, mint 30%-ért felel, a PC2 már csak valahol 17%-ért, és így tovább… Az alábbi táblázatban látható, hogy az egyes főkomponensek (Dim.1 – Dim.10) mekkora részt képviselnek a teljes varianciában. Az utolsó oszlopban pedig ezek kumulatív értéke szerepel, azaz a második sorban az első két főkomponens együttes hatása, a harmadik sorban az első három főkomponens együttes hatása van, és így tovább. Az első két főkomponens a varianciának kb. 50%-át fedi le.

A főkomponensek tartalmi elemeit az úgynevezett loading plot segítségével is elemezhetjük. A kétdimenziós diagram vízszintes és függőleges tengelye a két legnagyobb főkomponens, a nyilak pedig az egyes tényezőket, a mi esetünkben a sportágakat jelölik. A tengelyek beosztása -1-től +1-ig terjed és azt jelzik, hogy mennyire erős a korrelációs együttható az egyes tényezők (vagyis sportágak) és a főkomponensek között. Például a távolugrás (Long.jump) korrelációs együtthatója az első főkomponenssel 0,75, a második főkomponenssel pedig -0,3. A körülbelül azonos irányba mutató sportágak egymással is pozitív korrelációban vannak, az ellentétes irányba mutatók között viszont negatív korreláció áll fenn. Például a diszkoszvetés (Discuss) és a súlylökés (Shot.put) egymással pozitív korrelációban vannak, hiszen aki messzebbre dobja el a diszkoszt, az valószínűleg a súlygolyót is messzebbre löki el. A 400 méteres síkfutás (400m) és a távolugrás (Long.jump) viszont negatívan hatnak egymásra. Ha két tényező (sportág) merőleges egymásra, akkor azok között nincs korreláció, ilyen például az 1500 méteres síkfutás (1500m) és a magasugrás (High.jump).

Viszont a nyilak hosszának is van jelentősége. Sokáig nem értettem, hogy ez a diagram tulajdonképpen mit is jelent, amíg meg nem láttam a következő ábrát:
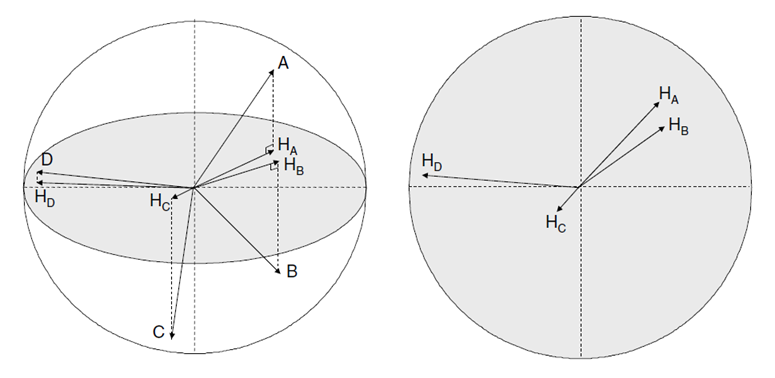
Nos, ez az ábra tulajdonképpen azt mutatja, hogy a loading plot a sokdimenziós tér kétdimenziós leképezése, a nyilak pedig az n-dimenziós irányok kétdimenziós leképezései. A probléma jelen esetben az, hogy amíg például a baloldali ábra bal oldalán a D és az E vektorok által bezárt szög - amely a két tényező korrelációját jellemzi – illetve a két vektor kétdimenziós leképezése által bezárt szög hasonló, vagyis a két vektor leképezése egészen jó. Vagyis a jobboldali kétdimenziós diagramon látható HD és HE vektorok aránylag jól leképezik a térbeli vektorokat. Ezzel szemben az A és a B vektorok esetében a két térbeli vektor bezárt szöge egészen nagy, míg ezek kétdimenziós leképezései kis szöget zárnak be. Az A és a B vektorok esetében a leképezés nem annyira biztos, a HA és a HB kétdimenziós leképezésvektorok alapján bizonytalanabb a két n-dimenziós térbeli vektor egymással bezárt szögének megítélése. Ráadásul minél rövidebb a kétdimenziós leképezésvektor, annál nagyobb lehet a gyanúnk, hogy az adott tényező inkább más főkomponensek hatását erősíti, nem pedig azt, amiket kiválasztottunk az ábrázoláshoz. Valószínűleg, ha túl sok rövid vektor van a kétdimenziós diagramon, annál nagyobb lehet a gyanúnk, hogy a két kiválasztott főkomponensünk nem az igazi.
Összefoglalás
A cikkben egy gyakorlati példa alapján próbáltam bemutatni hogyan használjuk a főkomponens elemzést soktényezős adatsorok megismerésére és elemzésére. A tízpróbázók adatai alapján egészen sok érdekes következtetést sikerült leszűrni annak ellenére, hogy egyáltalán nem értek a tízpróbához. El tudom képzelni, hogy valaki, aki ért is ehhez a sportághoz és ismeri az adatbázisban szereplő sportolókat, még sokkal több remek következtetést tudott leszűrni a nyers adatokból. A PCA-t egyébként még jó néhány más területen is alkalmazható, még akár képtömörítésre is, de az már egy másik cikk témája.
Források:
StatQuest: Principal Component Analysis (PCA), Step-by-Step
https://www.youtube.com/watch?v=_UVHneBUBW0&t=737s
Eigenvectors and eigenvalues | Chapter 14, Essence of linear algebra
https://www.youtube.com/watch?v=PFDu9oVAE-g
François Husson, Sébastien Lê, Jérôme Pagès: Exploratory Multivariate Analysis by Example using R, CRC Press Taylor Francis Group, 2011
FactomineR – Principal Component Analysis
http://factominer.free.fr/factomethods/principal-components-analysis.html
factoextra : Extract and Visualize the Results of Multivariate Data Analyses
https://rpkgs.datanovia.com/factoextra/
Principal component analysis (PCA) with R
https://www.youtube.com/watch?v=CTSbxU6KLbM
PCA (course 1/3): description of the method in a French way
https://www.youtube.com/watch?v=IuSbb3nq4aI&list=RDCMUCyz4M1pwJBNfjMFaUCHCNUQ&index=22
PCA (course 2/3): interpretation of the graph of individuals and variables
https://www.youtube.com/watch?v=msGKYXVdMxc
PCA (course 3/3): interpretation aids, use of categorical variables to interpret PCA results
https://www.youtube.com/watch?v=BOanMaBiN2w





