

Pályafutásom során egyetlenegyszer alkalmaztam kísérlettervezést, de nem fűződnek hozzá kellemes emlékek. Annyi mindenképpen megmaradt, hogy állati sokat dolgoztunk a minták legyártásával, az eredmény pedig megvolt egy félóra alatt. Ez a körülményesség eddig erősen riasztó volt számomra, ezért eddig nem voltam igazán lelkes, hogy nekiugorjak a témának. Aztán megrendeltem egy könyvet, elolvastam, és ez új lendületet adott a téma felfedezéséhez,
Paul Allen nem igazán ismert kis hazánkban, én is csak véletlenül akadtam rá a youtube-csatornájára. Először a beszéde és a kiejtése tetszett meg, de aztán felfedeztem, hogy mennyire egyszerűen és tömören fogalmaz meg olyan dolgokat, amelyeket mások rettentően el tudnak bonyolítani. Meg is rendeltem a "Design of Experiment for 21st Century Engineers" című 200 oldalas remekművet. A könyv elején egy kicsit több volt a marketing, mint amit ízlésesnek tartok, de alapvetően nem állított butaságokat, majd a könyv további része még inkább meggyőzött arról, hogy érdemes komolyabban foglalkozni ezzel a dologgal.
A kísérlettervezés célja tömören annyi, hogy a lehető legtöbb információt gyűjtsünk össze és ismerjünk meg egy összetett és bonyolult jelenségről a lehető legkevesebb munka és energia befektetésével. Az olyan összetett jelenségek megértése, ahol van 5-10 bemeneti jellemző (ezeket hívjuk faktoroknak), amelyek valamilyen módon befolyásolhatják a vizsgált jelenség eredményét. Ennyi paraméter esetében már nem mindig evidens, hogy mely paraméterektől függ a végeredmény és melyektől nem, illetve az sem, hogy melyik jellemző hatása mennyire erős.
Arról nem is beszélve, ha két vagy több bemenő jellemző együttes hatása befolyásolja a végeredményt. Ezt interakciónak nevezzük, ezt Paul egy egyszerű példával mutatta be:
Tegyük fel, hogy azt vizsgáljuk, hogy melyik jellemző befolyásolja a kávé édességének mértékét. A két paraméterünk a cukor mennyisége a kávéban, a másik pedig a kávé megkeverése a kiskanállal. Ha csak szimplán beletesszük a cukrot a kávéba, de nem keverjük meg, akkor a cukor leül a csésze aljára és a kávé íze keserű lesz, amikor megkóstoljuk. Hasonlóképpen igaz, hogy ha a kávét csak kevergetjük, de nem teszünk bele cukrot, akkor a kávé ismét csak nem lesz édes. Akkor lesz csak édes, ha beletesszük a cukrot és meg is keverjük, azaz a végeredményt csak a két tényező együttes hatása befolyásolja, egyenként nem, vagy nem olyan mértékben. Ezt nevezzük a két tényező interakciójának. Vagyis egy kísérletterv segítségével nemcsak az egyedi tényezők hatását, hanem több különféle tényező interakciójának hatásait is vizsgálhatjuk.
A hétköznapi életben a műszaki problémák megoldása során általában szubjektív tényezők alapján kiválasztott egyedi jellemzők hatásait szoktuk vizsgálni a hibaok keresése során. Ez sajnos vagy alacsony hatékonyságú, vagy pedig hosszadalmas és költséges, vagy mindkettő. A kísérlettervezés célja az, hogy úgy adjon teljes képet az adott jelenségről, hogy közben minimalizálja a költségeket. Ráadásul sok esetben a bemeneti tényezők bizonyos értékeit fizikai korlátok miatt nem is tudjuk kipróbálni. A későbbiekben látni fogjuk majd, hogy a kísérlettervezés segítségével a bemeneti tényezők olyan értékei esetében is meg tudjuk állapítani a jelenség eredményét, amelyet a valóságban ki sem próbáltunk.
A kísérlettervezés során a kísérleteinket ugyanis általában úgy tervezzük meg, hogy a bemeneti tényezőknek csak 2-3 értékét próbáljuk ki a valóságban, mégis teljes képet kapunk a bemeneti értékek teljes terjedelméről a vizsgált tartományban. Nézzük meg ezt egy példán keresztül:
A példánkban egy bizonyos papír gyártási folyamatát vizsgáljuk, az a cél, hogy a papír minél erősebb legyen. A mérnökök szerint három bemeneti tényező határozza meg a papír minőségét. Az alapanyaghoz hozzáadott keményfa mennyisége, a papír préselésekor alkalmazott nyomás és a főzési idő. A mérnökök az egyes bemeneti tényezők esetében a következő alacsony és magas értékeket választották ki:
keményfa tartalom: 2% - 6%
présnyomás: 400 - 650 psi
főzési idő: 3 óra - 4 óra
A következő lépésben ezeket az alacsony és magas értékeket "kódoljuk", ami annyit tesz, hogy az alacsony értékeket rendre -1-gyel, a magas értékeket pedig +1-el helyettesítjük. Ennek így elsőre talán nem sok értelmét látod, de a későbbiekben kiderül majd, hogy nagyon is fontos.
| -1 | 1 | |||
| Keményfa tartalom % (K) | 2% | 6% | ||
| Présnyomás psi (P) | 400 | 650 | ||
| Főzési idő óra (F) | 3 | 4 | ||
Mivel csak 3 bemeneti tényezőt vizsgálunk, ezért ha a három tényező minden (-1; +1) kombinációját kipróbáljuk, akkor is csak 8 különböző esetet kell létrehoznunk. Ezt nevezzük teljes faktoriális design-nak (full factorial design). A következő ábrán a három faktor 8 különféle -1; +1 kombinációja látható. Az első eset például az, amikor a keményfa tartalom (X1), a présnyomás (X2) és a főzési idő (X3) is az alacsony (-1) értéket veszi fel. A második esetben a keményfa tartalom a magas (+1), a présnyomás és a főzési idő az alacsony (-1) értéket veszi fel.
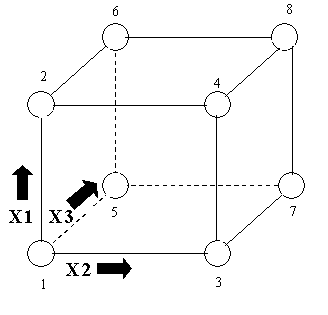
Vagyis összesen 8 különböző esetet kell megvizsgálnunk. Egy kicsit jobban megvizsgálva jól látható a -1-ek és a +1-ek mintázata.
| Keményfa tartalom | Présnyomás | Főzési idő |
| -1 | -1 | -1 |
| -1 | -1 | 1 |
| -1 | 1 | -1 |
| -1 | 1 | 1 |
| 1 | -1 | -1 |
| 1 | -1 | 1 |
| 1 | 1 | -1 |
| 1 | 1 | 1 |
A legegyszerűbb esetben ez 8 darab papír legyártását jelenti! Persze azért illik ennél több erőfeszítést beletenni a dologba, mert ha a faktorok minden egyes kombinációjával csak egyetlen ív papírt készítünk el, akkor az azonos technológiával legyártott papírívek közötti varianciát nem fogjuk érzékelni. Ez esetben a team úgy döntött, hogy minden egyes variáció esetében két ív papírt fognak gyártani, vagyis így a bemeneti tényezők minden kombinációjához két minta és ezáltal két mért érték fog tartozni. Ezeket nevezzük ismétléseknek (repeats vagy replications).
Most ugyan eltekintünk ettől, de a fent említett 16 ív papírt véletlenszerű sorrendben ajánlott elkészíteni, egyrészt hogy az előző hasonló beállítások elemzése befolyásolja az éppen elkészített minták eredményeit. A másik fontos érv a véletlenszerű sorrend mellett az, hogy ha a gyártás sorrendjében vizsgáljuk meg az eredményeket, úgy kiderülhetnek olyan nem várt hatások (például trendek, vagy szabályszerű mintázatok), amelyekkel eddig nem számoltunk. Ezt randomizálásnak hívjuk.
Természetesen kiderülhetnek olyan problémák, amelyek a randomizálás során komoly nehézséget okozhatnak (például egy hosszadalmas vagy bonyolult átállás vagy beállítás), amelyeket érdemes mégiscsak együtt kezelni, akkor lehetséges az eseteket összevontan kezelni, vagyis az eseteket blokkokba tudjuk szervezni. Ilyen esetekben lehet a blokkok sorrendjét, illetve a blokkokon belül az egyes eseteteket is randomizálni lehet.
Noha a fizikai folyamat előkészítése és a minták legyártása a módszer leginkább időrabló része, ezt most itt elegánsan átugrom. Nem megyek bele olyan fontos részletekbe, mint az elkészített minták megmérésének problémaköre, a mérőrendszer elemzés elkészítése, a minták azonosítása és nyomonkövetése és más hasonló időrabló tevékenységek.
Ugorjunk oda, hogy elkészült az adatsorunk:
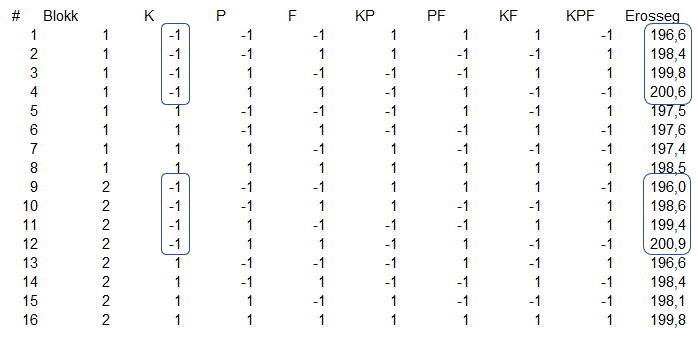
| # | Blokk | K | P | F | Erosseg |
| 1 | 1 | -1 | -1 | -1 | 196,6 |
| 2 | 1 | -1 | -1 | 1 | 198,4 |
| 3 | 1 | -1 | 1 | -1 | 199,8 |
| 4 | 1 | -1 | 1 | 1 | 200,6 |
| 5 | 1 | 1 | -1 | -1 | 197,5 |
| 6 | 1 | 1 | -1 | 1 | 197,6 |
| 7 | 1 | 1 | 1 | -1 | 197,4 |
| 8 | 1 | 1 | 1 | 1 | 198,5 |
| 9 | 2 | -1 | -1 | -1 | 196,0 |
| 10 | 2 | -1 | -1 | 1 | 198,6 |
| 11 | 2 | -1 | 1 | -1 | 199,4 |
| 12 | 2 | -1 | 1 | 1 | 200,9 |
| 13 | 2 | 1 | -1 | -1 | 196,6 |
| 14 | 2 | 1 | -1 | 1 | 198,4 |
| 15 | 2 | 1 | 1 | -1 | 198,1 |
| 16 | 2 | 1 | 1 | 1 | 199,8 |
Ebben a formában az eredmények nem mutatnak semmilyen szabályszerűséget, az összefüggések majd a későbbiekben fognak kiderülni. Viszont az adatok feldolgozása előtt még van egy feladatunk, a faktorok interakcióinak hozzáadása. Szerencsére kevés faktorunk van, ezért az interakciók lehetősége is korlátozott. Összesen 4 különféle interakciónk van:
- KP a keményfa tartalom és a présnyomás,
- PF a présnyomás és a főzési idő,
- KF a keményfatartalom és a főzési idő,
- KPF pedig mind a három tényező interakciója.
Az interakciókat hozzá lehet adni a fenti táblázathoz. Azonban azt tisztáznunk kell, hogy mit jelentenek az interakciók ebben az esetben:
| # | Blokk | K | P | F | KP | PF | KF | KPF | Erosseg |
| 1 | 1 | -1 | -1 | -1 | 1 | 196,6 | |||
| 2 | 1 | -1 | -1 | 1 | 198,4 | ||||
| 3 | 1 | -1 | 1 | -1 | 199,8 | ||||
| 4 | 1 | -1 | 1 | 1 | 200,6 | ||||
| 5 | 1 | 1 | -1 | -1 | 197,5 | ||||
| 6 | 1 | 1 | -1 | 1 | 197,6 | ||||
| 7 | 1 | 1 | 1 | -1 | 197,4 | ||||
| 8 | 1 | 1 | 1 | 1 | 198,5 | ||||
| 9 | 2 | -1 | -1 | -1 | 196,0 | ||||
| 10 | 2 | -1 | -1 | 1 | 198,6 | ||||
| 11 | 2 | -1 | 1 | -1 | 199,4 | ||||
| 12 | 2 | -1 | 1 | 1 | 200,9 | ||||
| 13 | 2 | 1 | -1 | -1 | 196,6 | ||||
| 14 | 2 | 1 | -1 | 1 | 198,4 | ||||
| 15 | 2 | 1 | 1 | -1 | 198,1 | ||||
| 16 | 2 | 1 | 1 | 1 | 199,8 |
Az első sorban a KP oszlopban lévő +1 úgy jött ki, hogy egyszerűen összeszoroztam a K és a P oszlopokban az adott sorhoz tartozó +1-eket és -1-eket, ez esetben (-1) * (-1) = 1.
| # | Blokk | K | P | F | KP | PF | KF | KPF | Erosseg |
| 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 | 196,6 |
| 2 | 1 | -1 | -1 | 1 | 198,4 | ||||
| 3 | 1 | -1 | 1 | -1 | 199,8 | ||||
| 4 | 1 | -1 | 1 | 1 | 200,6 | ||||
| 5 | 1 | 1 | -1 | -1 | 197,5 | ||||
| 6 | 1 | 1 | -1 | 1 | 197,6 | ||||
| 7 | 1 | 1 | 1 | -1 | 197,4 | ||||
| 8 | 1 | 1 | 1 | 1 | 198,5 | ||||
| 9 | 2 | -1 | -1 | -1 | 196,0 | ||||
| 10 | 2 | -1 | -1 | 1 | 198,6 | ||||
| 11 | 2 | -1 | 1 | -1 | 199,4 | ||||
| 12 | 2 | -1 | 1 | 1 | 200,9 | ||||
| 13 | 2 | 1 | -1 | -1 | 196,6 | ||||
| 14 | 2 | 1 | -1 | 1 | 198,4 | ||||
| 15 | 2 | 1 | 1 | -1 | 198,1 | ||||
| 16 | 2 | 1 | 1 | 1 | 199,8 |
Hasonlóképpen alakulnak a PF, KF és a KPF oszlopok is. Természetesen a KPF oszlopban szereplő (-1) úgy jött ki, hogy a K, P és F oszlopokban lévő -1-eket szoroztam össze. A teljes táblázat így a következőképpen alakul.
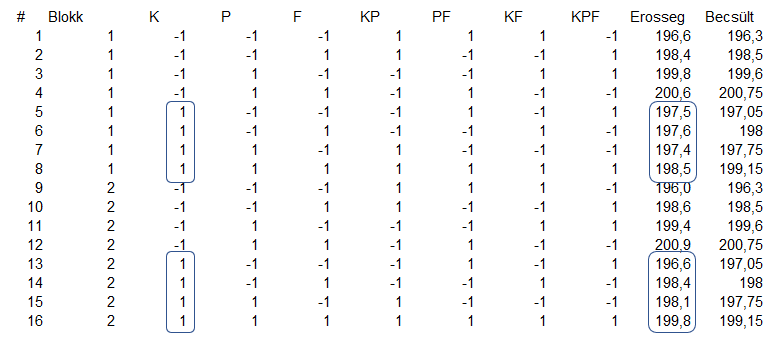
| # | Blokk | K | P | F | KP | PF | KF | KPF | Erosseg |
| 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 | 196,6 |
| 2 | 1 | -1 | -1 | 1 | 1 | -1 | -1 | 1 | 198,4 |
| 3 | 1 | -1 | 1 | -1 | -1 | -1 | 1 | 1 | 199,8 |
| 4 | 1 | -1 | 1 | 1 | -1 | 1 | -1 | -1 | 200,6 |
| 5 | 1 | 1 | -1 | -1 | -1 | 1 | -1 | 1 | 197,5 |
| 6 | 1 | 1 | -1 | 1 | -1 | -1 | 1 | -1 | 197,6 |
| 7 | 1 | 1 | 1 | -1 | 1 | -1 | -1 | -1 | 197,4 |
| 8 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 198,5 |
| 9 | 2 | -1 | -1 | -1 | 1 | 1 | 1 | -1 | 196,0 |
| 10 | 2 | -1 | -1 | 1 | 1 | -1 | -1 | 1 | 198,6 |
| 11 | 2 | -1 | 1 | -1 | -1 | -1 | 1 | 1 | 199,4 |
| 12 | 2 | -1 | 1 | 1 | -1 | 1 | -1 | -1 | 200,9 |
| 13 | 2 | 1 | -1 | -1 | -1 | 1 | -1 | 1 | 196,6 |
| 14 | 2 | 1 | -1 | 1 | -1 | -1 | 1 | -1 | 198,4 |
| 15 | 2 | 1 | 1 | -1 | 1 | -1 | -1 | -1 | 198,1 |
| 16 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 199,8 |
Most következik a folyamat leglényegesebb része. A teendőnk meglepő módon sokkal egyszerűbb, mint azt elsőre gondolnánk. A teendőnk tulajdonképpen annyi, hogy oszloponként összehasonlítjuk az alacsony és a magas állapotokhoz tartozó eredmények átlagait. Például a K oszlop esetében ez a következőképpen alakul:

A magas értékek átlaga hasonlóképpen számolható ki:

A kétféle átlag közötti különbség adja meg, hogy a keményfa tartalom változása milyen hatással van a papír erősségére. A többi oszlop esetében hasonlóképpen számolhatók az alacsony és a magas állapotok átlagai közötti különbségek, az interakciók esetében is.

Az alacsony és a magas értékek átlagainak különbsége a következőképpen alakul:

Igazából arra vagyunk kíváncsiak, hogy mennyire erős hatása van az adott tényező változásának, vagyis mekkora az alacsony és a magas állapotot összekötő egyenes meredeksége.
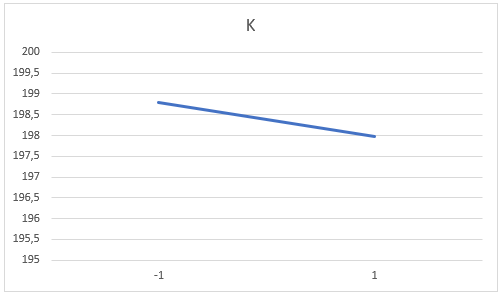
A keményfa tartalom esetében a keményfa tartalom növekedésének hatására a papír erőssége enyhén csökken. Az természetesen egy fontos kérdés, hogy ez a kapcsolat a keményfa tartalom és a papír erőssége között vajon lineáris kapcsolat-e, de első körben ezt nem vizsgáljuk, ez talán egy következő cikk témája lesz.
De mi adja meg az egyenes meredekségét? Az egyenes meredeksége annyit tesz, hogy az x-értékek (vízszintes tengely) egységnyi változása mekkora egységnyi változást indukál az y-értékeiben (függőleges tengely). A keményfa tartalom esetében a vízszintes tengely értékei -1-ről +1-re változtak, a függőleges tengely értékei pedig 198,7875-ről 197,9875-re csökkentek. Vagyis az egyenes meredeksége
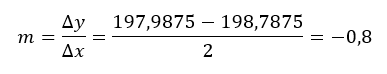
Ez azt jelenti, hogy ez egy függvény? Tulajdonképpen igen! Tehát nemcsak arról van szó, hogy van egy alacsony és egy magas állapotunk, amelynek ismerjük a kimeneti eredményét, hanem -1 és +1 között bármilyen x értékhez ki tudjuk számolni a hozzá tartozó y értéket, jelen esetben a papír erősségét. Például a 0 értékhez tartozó erősség
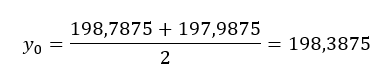
Nos, fokozzuk ezt még egy kicsit. Először is számoljuk ki a vonatkozó egyenesek meredekségeit a fő faktorokra és az interakciókra is:
| # | K | P | F | KP | PF | KF | KPF |
| -1 | 198,7875 | 197,4625 | 197,675 | 198,85 | 198,4625 | 198,5125 | 198,2 |
| 1 | 197,9875 | 199,3125 | 199,1 | 197,925 | 198,3125 | 198,2625 | 198,575 |
| Különbség | -0,8 | 1,85 | 1,425 | -0,925 | -0,15 | -0,25 | 0,375 |
| koeff.k | -0,4 | 0,925 | 0,7125 | -0,4625 | -0,075 | -0,125 | 0,1875 |
A meredekségeket összehasonlítva képet kaphatunk arról, hogy melyik tényező mennyire van hatással a folyamat eredményére. A présnyomás (P) van a jelek szerint leginkább hatással a papír erősségére, vagyis minél nagyobb a présnyomás, annál erősebb lesz a papír. A főzési idő növelése szintén erősíti a papírt, noha nem annyira, mint a présnyomás növelése. Vagyis ha a keményfa tartalmat a minimumon tartjuk, a présnyomást és a főzési időt pedig a maximumra növeljük, akkor a papír erőssége maximális lesz.
De hogyan tudjuk ezt ellenőrizni?
Nos, amikor előállítottuk a kísérleti adatsorunkat, tulajdonképpen egy többváltozós lineáris regresszió elemzés adatsorát állítottuk elő, amely az összetett rendszer minden tényezőjét figyelembe veszi. Csak emlékeztetőül, a többváltozós lineáris regresszió egyenlete a következő:
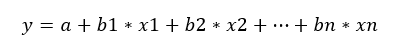
Adaptáljuk ezt a mi esetünkre:

Vagyis a fentebb kiszámolt koefficiensek és az egyes faktorok esetén kiválasztott x értékek szorzata megadja majd a beállított faktorokhoz tartozó eredményt, azaz a papír erősségét. De mi az a titokzatos 'a' az egyenletben, amely az egyenes és az y-tengely metszéspontját jelöli? Ez tulajdonképpen a 16 mért érték átlaga,
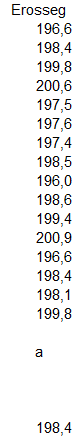
Ezek alapján most már képesek vagyunk kiszámítani a papír erősségét a bemeneti faktorok meredekségei alapján.
| # | Blokk | K | P | F | KP | PF | KF | KPF | Erosseg | Becsült |
| 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 | 196,6 | 196,3 |
| 2 | 1 | -1 | -1 | 1 | 1 | -1 | -1 | 1 | 198,4 | 198,5 |
| 3 | 1 | -1 | 1 | -1 | -1 | -1 | 1 | 1 | 199,8 | 199,6 |
| 4 | 1 | -1 | 1 | 1 | -1 | 1 | -1 | -1 | 200,6 | 200,75 |
| 5 | 1 | 1 | -1 | -1 | -1 | 1 | -1 | 1 | 197,5 | 197,05 |
| 6 | 1 | 1 | -1 | 1 | -1 | -1 | 1 | -1 | 197,6 | 198 |
| 7 | 1 | 1 | 1 | -1 | 1 | -1 | -1 | -1 | 197,4 | 197,75 |
| 8 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 198,5 | 199,15 |
| 9 | 2 | -1 | -1 | -1 | 1 | 1 | 1 | -1 | 196,0 | 196,3 |
| 10 | 2 | -1 | -1 | 1 | 1 | -1 | -1 | 1 | 198,6 | 198,5 |
| 11 | 2 | -1 | 1 | -1 | -1 | -1 | 1 | 1 | 199,4 | 199,6 |
| 12 | 2 | -1 | 1 | 1 | -1 | 1 | -1 | -1 | 200,9 | 200,75 |
| 13 | 2 | 1 | -1 | -1 | -1 | 1 | -1 | 1 | 196,6 | 197,05 |
| 14 | 2 | 1 | -1 | 1 | -1 | -1 | 1 | -1 | 198,4 | 198 |
| 15 | 2 | 1 | 1 | -1 | 1 | -1 | -1 | -1 | 198,1 | 197,75 |
| 16 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 199,8 | 199,15 |
Az első sor például

Összehasonlítva a táblázat utolsó két oszlopát, jól látható, hogy a mért és a meredekségek alapján becsült értékek mennyire közel vannak egymáshoz. Ha megvizsgálom a kísérletsorozat során kapott eredményeket és a modell alapján becsült értékeket, akkor egy egészen szoros összefüggést látok a két adatsor között.
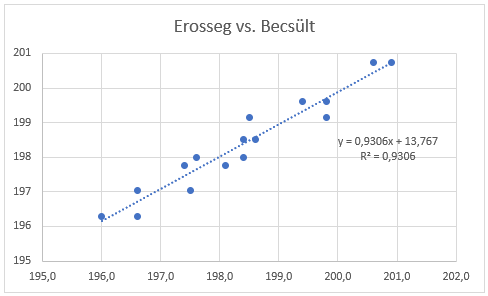
A diagram jobb oldalán lévő R2 (R-négyzet vagy R-squared) jelzi, hogy a modell varianciája hány százalékban magyarázza meg a tapasztalati úton kapott eredményeket. A 93% igen jónak számít.
Összefoglalás:
A kísérlettervezés egy igen praktikus eszköz olyan problémák megoldására, amelyek esetében sokféle bemeneti tényező befolyásolja egy jelenség vagy egy folyamat végeredményét. Relatíve kevés kísérlet végrehajtásával komplett képet kaphatunk a vizsgált jelenségről vagy meghatározhatjuk egy folyamat paramétereinek optimális beállítását. Még mélyebben is bele lehetett volna menni a részletekbe, de a cikk így is hosszú és kimerítő lett, úgyhogy ha eddig eljutottál kedves olvasó, akkor minden tiszteletem a tiéd!
Végezetül essék szó arról, hogy hány kísérletet takarítottunk meg azzal, hogy kísérlettervezést alkalmaztunk. A keményfa tartalom esetében ha a határértékként megállapított 2% és 6% között csak százalékonként léptetjük az értékeket, akkor 5 különböző kísérletet kellett volna elvégeznünk. A présnyomás esetében a 400 és a 650 psi között 250 különféle érték van, a főzési idő esetében pedig 2 érték van, a 3 és a 4 óra, de ezt lehetne tovább is osztani, mondjuk 15 perces léptékekben. Ekkor 5 * 250 * 5 = 6250 kísérletet kellett volna elvégeznünk ugyanennyi tudás megszerzéséhez. A kísérlet "zanzásítása" jól sikerült!
Forrás:
Paul Allen: Design of Experiment for 21st Century Engineers, Complexity Made Simple
www.hulu.com




