Az előző cikkben (Karl Pearson és a rulettkerék rejtélye – Khí-négyzet próba az illeszkedés vizsgálatára) levezettem a khí-négyzet próbát az illeszkedés vizsgálatára felhasználva Karl Pearson eredeti adatait a rulett sorozatok és az érmefeldobás sorozatok vizsgálatára. Mivel mindig érdekes az, hogy egy statisztikai szoftver hogyan dolgozza fel az adatokat, illetve hogyan tálalja elénk a tesztek eredményeit, most is szeretném nektek lépésről lépésre bemutatni, hogy hogyan készíteném el ezt az elemzést a Minitab statisztikai elemző programmal.
Szokásomhoz híven most is átmásoltam az adatokat a Minitab programba, viszont ez esetben egy kicsit át kellett alakítanom az adatsort, mert a Minitab elsősorban oszlopokat kezel, nekem pedig sorokban vannak az adataim. Persze nincs is szükségem az összes adatra, ebben az esetben elegendőek a kategóriák nevei, illetve a megfigyelt és az elméleti gyakoriságok adatai kategóriánként. Szerencsére a táblázatkezelő programoknak van egy hasznos tulajdonsága, ha kimásolsz egy cellasort CTRL-C-vel, akkor beillesztheted transzponálva oszlopként, így a dolgom jelentősen egyszerűbb lett és pillanatok alatt összeállítottam a Minitab táblázatkezelőjében a kívánt adathalmazt. A Minitab táblázatban a ’Sorozat’ oszlop tartalmazza a kategóriák neveit, azaz az egyszeres, kétszeres, stb. sorozatok hosszát, az ’R_valos’ oszlop a rulett sorozatok (Roulette) tapasztalt gyakoriságait, az ’R_Elmeleti’ oszlop pedig a rulett sorozatok elméleti gyakoriságait. Hasonlóképpen a ’T_valos’ oszlop az érmefeldobás sorozatok (Tossing) tapasztalt gyakoriságait, a ’T_Elmeleti’ oszlop pedig az érmefeldobás sorozatok elméleti gyakoriságait. Azért adtam ilyen rövidebb neveket, mert ezeket a Minitab jobban kezeli, mint a hosszúakat. A követhetőség kedvéért idetettem mellé az eredeti táblázatot is, hogy egyszerűen össze tudd hasonlítani az adatokat.

Amikor ezzel megvoltam, akkor az eddigiekhez hasonlóan elindítottam a tesztet. Jelen esetben ez a teszt a ’Stat’ menü ’Tables’ almenüjében található.
A menüpontra kattintással ismételten egy adatbeviteli ablakba jutottam. Először a rulett sorozatok eredményeit elemeztem. Az elemzéshez meg kell mondani a Minitab-nak, hogy melyik oszlopok tartalmazzák a teszt elvégzéséhez szükséges adatokat. …

Az ’Observed counts’ (Észlelt gyakoriságok) mező tartalmazza az észlelt gyakoriságokat, itt először az ’R_valos’ oszlopot adtam meg a rulett sorozatok vizsgálatához. A következő mező a ’Category names (Optional)’, itt meg lehet adni annak az oszlopnak a nevét, amely a kategóriák neveit tartalmazza. Ez nem kötelező, ha nem adom meg, akkor sorszámokkal látja el a Minitab az egyes kategóriákat. Ebben a példában akár el is hagyhatnám, de azért inkább megadom. A ’Categorical data’ mezőt akkor használnám, ha a nyers adatok állnának a rendelkezésemre, tehát a rulett sorozatok esetében az egyes rulett pörgetések eredményei vagy az érmefeldobások esetében a feldobások eredményei azok sorrendjében. A teszt beállításainál többféle lehetőség is van arra, hogy az egyes kategóriák gyakoriságait hogyan vegye figyelembe a program. Az ’Equal proportions’ (Egyforma gyakoriságok) lehetőség választása esetén a Minitab feltételezi, hogy minden egyes kategória ugyanolyan gyakorisággal fordulhat elő. A ’Specific proportions’ (Megadott gyakoriságok) lehetőség kiválasztásával megadható egy oszlop, amelyben az elméleti gyakoriságok szerepelnek, vagy egyenként begépelhetők ide a gyakoriságok értékei. Vigyázat! Itt gyakorisági értékeket, azaz 0 és 1 közötti számokat, azaz százalékokat kér a program és nem darabszámokat! A ’Proportions specified by historical counts’ (Korábbi számolások alapján megadott gyakoriságok) lehetőség kiválasztásával az előzőhöz nagyon hasonlító lehetőséghez jutok, megadhatom a megfelelő oszlop nevét, vagy begépelhetem az elméleti gyakoriságokat konstansokként. Jelen esetben én ezt a lehetőséget választottam és megadtam az ’R_Elmeleti’ oszlopot.

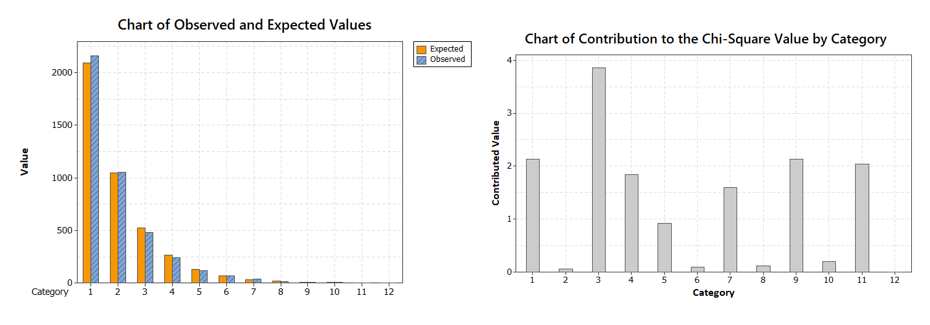
A teszthez kétféle grafikont lehet kérni, a felső grafikon tartalmazza a valós és az elméleti gyakoriságok összehasonlítását kategóriánként, a másik diagram pedig azt ábrázolja, hogy az egyes kategóriák értékei milyen mértékben befolyásolják a khí-négyzet értékét, Az utolsó jelölőnégyzet segítségével el lehet dönteni, hogy a második grafikonon a kategóriákat az eredeti sorrendben ábrázolja (ha nem jelölöm be a jelölőnégyzetet), vagy nagyság szerint csökkenő sorrendben ábrázolja az adatokat, mint egy Pareto-diagramot (ha bejelölöm a jelölőnégyzetet).
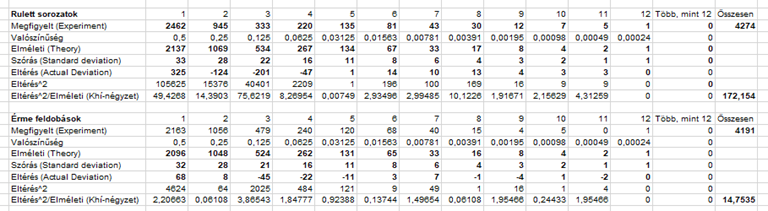
És akkor lássuk az eredményeket. Az áttekinthetőség kedvéért itt is ide másoltam az előző cikkben készített táblázatot, hogy könnyen össze lehessen hasonlítani az adatokat:
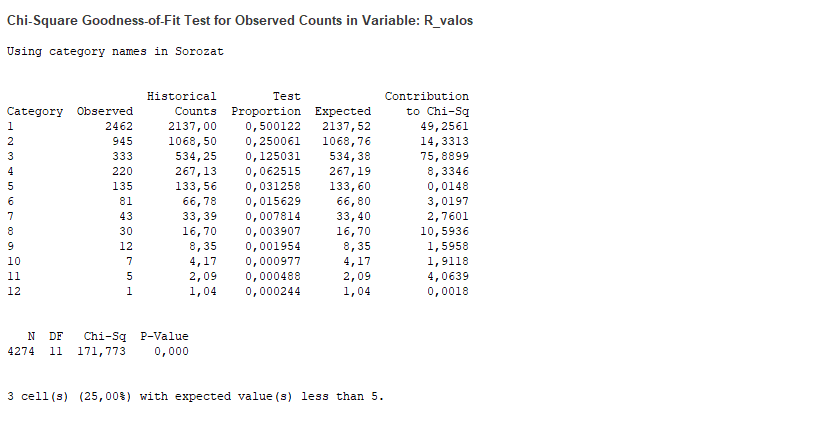
A kapott jelentés két részből áll. Sajnos a program írója itt nem vesződött a nullhipotézis és az ellenhipotézis megadásával (nehogy tudjuk, hogy mit csinálunk?), így a teszt riport egyrészt áll az összefoglaló táblázatból, másrészt a hipotézis vizsgálatból. A teszt utolsó sorában a Minitab felhívja a figyelmet arra, hogy három olyan kategória is van, amelynél az elméleti érték (Expected value) kisebb ötnél. Ezt a feltételt az előző bejegyzésben a teszt kiinduló feltételeként adtam meg és ezt érdemes figyelembe venni az eredmények elemzésekor, de mivel összesen 12 kategóriám van és rengeteg adatom, ezért talán ez a tény nem fogja érvényteleníteni a teszt eredményét. A táblázatból jól látható, hogy az ’Observed’ és a ’Historical counts’ oszlopokban vannak az észlelt és az elméleti gyakoriságok. A ’Test proportions’ oszlopban a kiszámított elméleti százalékos gyakoriságok értékei találhatók, ezek kiszámítási módját az előző cikkben a tablázatkezelős megoldásnál elmagyaráztam. Az ’Expected’ oszlopban a program a ’Test proportions’ alapján kiszámította az elméletileg elvárt gyakorisági darabszámokat. Ez egy kicsit ismétlésnek tűnik, de ha az elméleti százalékos gyakoriságokat adtam volna meg, akkor ennek így lenne értelme. Végül a ’Contribution to Chi-Sq’ oszlopban az egyes kategóriákhoz tartozó khí-négyzet részeredmények vannak felsorolva.
A hipotézis vizsgálati részben a program először megadta ’N’ értékét, amely az összes megfigyelés mennyiségét tartalmazza (4274 db), a ’DF’ mező a Degrees of Freedom-ot, azaz a Szabadsági fokok számát tartalmazza, amely a már korábban megadott 11, a khí-négyzet értéke 171,773, amely majdnem ugyanannyi, mint az általam kiszámított 172,154. Sajnos a khí-négyzet eloszlás alapján kiszámított határértéket itt sem adja meg a program, csak a titokzatos p-értéket, amely jelen esetben 0,000. A Minitab help-je alapján meg lehet tudni, hogy ez azt jelenti, hogy a nullhipotézist elvetjük, azaz a rulett sorozatok tapasztalt gyakoriságai nem illeszkednek az elméleti gyakoriságokhoz, de ugye ez nem tartozik mindenkire, csak azokra, akik értenek is hozzá.
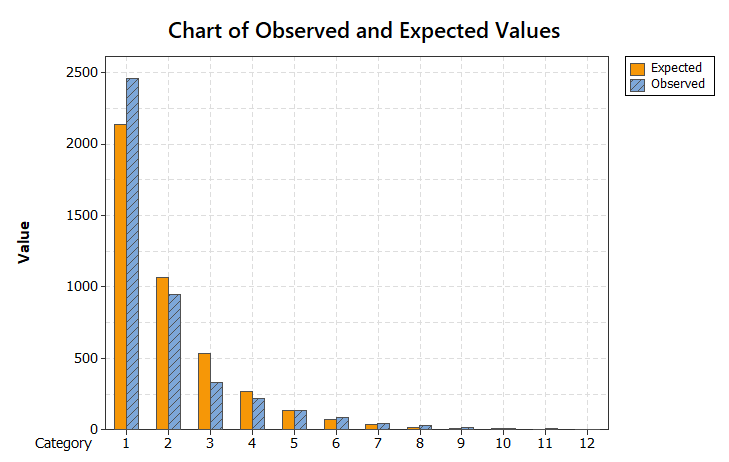
Az első grafikonon jól látható, hogy az egyelemű sorozatok sokkal gyakrabban fordulnak elő, mint az elméletileg kiszámított vagy elvárt gyakoriság, a két-, három-, és többelemű sorozatok viszont kevesebbszer, mint az elvárt lenne.
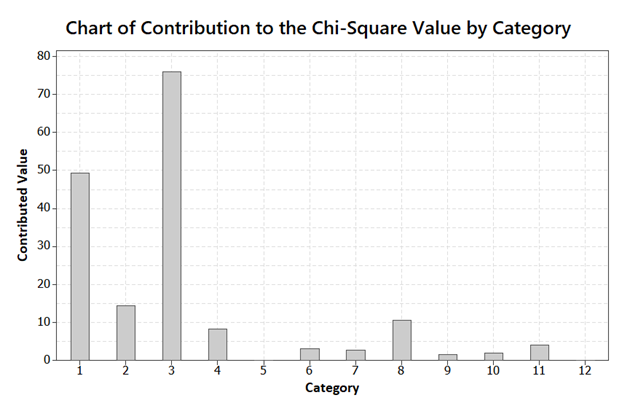
Ebből a grafikonból, viszont az derül ki, hogy a háromelemű (75,8899) és az egyelemű (49,2561) sorozatok járulnak hozzá leginkább a khí-négyzet magas értékéhez.
És most nézzük meg az érmefeldobásokat. A teszt alapadatait hasonlóképpen állítjuk be, mint a rulett sorozatok esetében.
A teszt riport eredménye is hasonló felépítésű, de azért jelentős különbségeket tapasztalok a rulett sorozatokhoz képest, mert itt sokkal kisebbek a khí-négyzet változó kategóriánként kapott eredményei, és ezáltal a hipotézis vizsgálatnál is sokkal kisebb khí-négyzet összeget kapott a Minitab. Szerencsére khí-négyzet értékére itt is hasonló értéket kaptunk, mint a táblázatkezelőben, és a teszt eredménye is hasonló lett. Mivel a titokzatos p-érték itt 0,181 lett, amely nagyobb, mint 0,05 (95%-os megbízhatósági szint esetén), ezért a nullhipotézist elfogadjuk és kijelentjük, hogy az érmefeldobás sorozatok gyakoriságai megfelelnek az elméletileg kiszámított gyakoriságoknak, tehát itt azt kaptam, amit vártam.
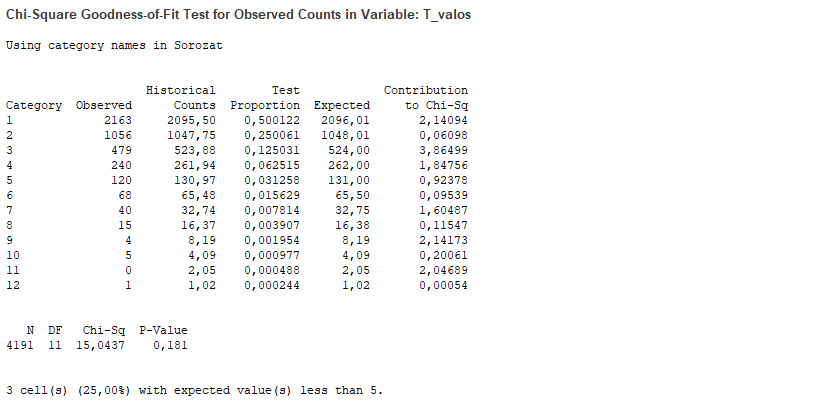
A grafikonokról az előzőekhez hasonlóan le lehet olvasni az észlelt és az elméleti gyakoriságok különbségeit minden kategóriában, de itt nincsenek annyira kiugró értékek, mint a rulett sorozatok esetében.