Ahogyan a normál vagy a khí-négyzet eloszlás esetében is érdekes lehet, hogy egy adatsor ilyen eloszlást követ-e, úgy az is érdekes lehet, hogy egy elméletileg Poisson-eloszlást követő adathalmaz vajon tényleg megfelel-e az elvárt követelményeknek, azaz tényleg Poisson-eloszlású-e. Hogy csak egy aktuális példát említsek, számítógép szerverek esetében a szerverre beérkező véletlenszerű szolgáltatási kérések időegységre eső száma is Poisson-eloszlást követ. Ha ez a feltétel nem teljesül, akkor felmerül a hackertámadás gyanúja. Ezt a tulajdonságot például a hálózati forgalom elemzésére is fel lehet használni.
De térjünk vissza az eredeti témára. A Minitab hivatalos blogján találtam ezt az elemzést, amely pontosan arról szól, amire most szükségem van, ezért úgy döntöttem, hogy megosztom a sztorit veletek.
A feladat tehát az, hogy a Trónok Harca sorozat mind a nyolc évadának összes epizódjából összegyűjtött elhalálozások vajon természetes eloszlást mutatnak-e, avagy sem. Ha a halálozások száma Poisson-eloszlást követ, akkor feltételezhetjük, hogy az egyes részekben teljesen véletlenszerű, hogy hányan halnak meg, ha a halálozások száma nem követi a Poisson-eloszlást, akkor a halálozások eloszlása az epizódok között nem véletlenszerű. Ha a halálozások száma Poisson-eloszlás szerinti lenne, akkor akár meg is lehetne jósolni, hogy a következő fejezetekben hány ember halna meg (már persze ha a sorozat folytatódna).
Ha valaki szintén szeretne játszani az adatokkal, itt megtalálható az összes haláleset évadonként, epizódonként és az elhunytak neve szerint kigyűjtve.
Mielőtt belevágnánk az adatok elemzésébe, csak úgy mellékesen nézzük meg az adathalmaz összesítését mindösszesen …

… és évadonként is …
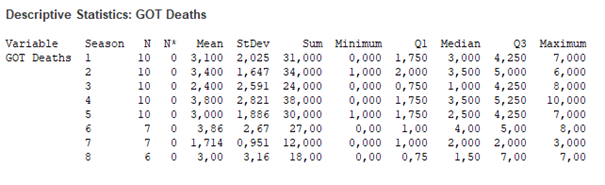
Már itt is lehet találni néhány tanulságos dolgot, például, hogy A 8 évad 70 epizódjában átlagosan 3,057 haláleset történt (ez lesz a mi esetünkben a λ értéke) vagy hogy évadonként vizsgálva a hetedik évad egy kicsit kilóg a sorból, mert ott csak 1,7 haláleset történt átlagosan epizódonként és ebben az évadban a halálesetek is egyenletesebben oszlottak el az egyes részek között. Ettől függetlenül a halálesetek átlagos száma egészen egyenletes.
Ezután végezzük el az illeszkedés vizsgálatát. Mivel ez is egy hipotézis vizsgálat, itt is meg kell adnunk a nullhipotézist (H0) és az ellenhipotézist (H1) is. A nullhipotézis az, hogy a halálesetek száma epizódonként Poisson-eloszlást mutat, az ellenhipozézis pedig az, hogy a halálesetek száma NEM Poisson-eloszlású.
A Poisson-illeszkedésvizsgálatot a Minitab-ban a ’Stat’ menü ’Basic Statistics’ almenüjében találjuk.
 A tesztet elindítva szokásosan egy ablak ugrik fel, ahol meg kell adnunk azt az oszlopot, amelyben a halálozási adatok találhatók.
A tesztet elindítva szokásosan egy ablak ugrik fel, ahol meg kell adnunk azt az oszlopot, amelyben a halálozási adatok találhatók.
 Mivel a ’GOT Deaths’ oszlopban a nyers adatok vannak, ezért a ’Frequency variable’ mezőt üresen hagytam. Ezután mást már nem kell tenni, csak az OK gombra kattintva elindítani a tesztet. Eredményként a következőt dobta a gép.
Mivel a ’GOT Deaths’ oszlopban a nyers adatok vannak, ezért a ’Frequency variable’ mezőt üresen hagytam. Ezután mást már nem kell tenni, csak az OK gombra kattintva elindítani a tesztet. Eredményként a következőt dobta a gép.
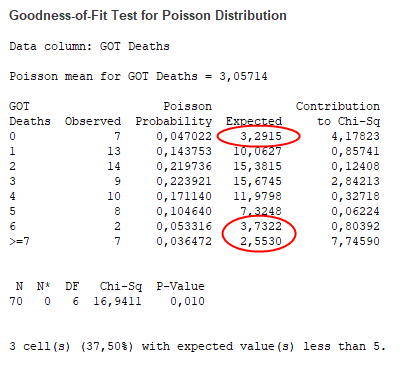 A teszt lefutott, de a Minitab jelezte, hogy 3 olyan ’Expected value’ érték van, amely kisebb ötnél. A Pearson-féle khí-négyzet próba esetén (hiszen ez is az), az nem jó, ha 5-nél kisebb az előfordulások száma, mert a teszt pontatlan eredményt ad. Ezen úgy lehet segíteni, ha összevonom azoknak az epizódoknak a számát, amelyekben 0 vagy 1 haláleset történt, illetve azokat, amelyekben 6, 7 vagy annál több. Így újra lefuttatva a tesztet már nem kaptam ilyen hibaüzenetet.
A teszt lefutott, de a Minitab jelezte, hogy 3 olyan ’Expected value’ érték van, amely kisebb ötnél. A Pearson-féle khí-négyzet próba esetén (hiszen ez is az), az nem jó, ha 5-nél kisebb az előfordulások száma, mert a teszt pontatlan eredményt ad. Ezen úgy lehet segíteni, ha összevonom azoknak az epizódoknak a számát, amelyekben 0 vagy 1 haláleset történt, illetve azokat, amelyekben 6, 7 vagy annál több. Így újra lefuttatva a tesztet már nem kaptam ilyen hibaüzenetet.
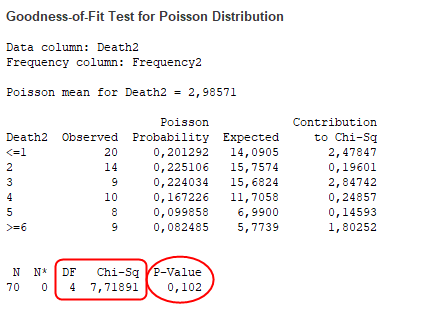
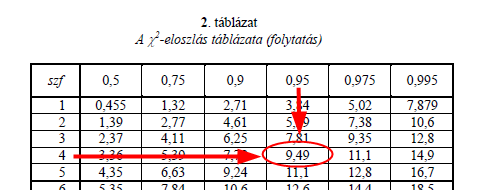
Ami itt lényeges a nullhipotézisről szóló döntéssel kapcsolatban az a ’P-Value’, amely itt 0,102, ami nagyobb, mint 0,05. Ez azt jelenti, hogy 95%-os valószínűséggel nem tudom elvetni a nullhipotézist, azaz van annak esélye, hogy az epizódonkénti halálesetek száma Poisson-eloszlást mutat. Szerencsére a kiszámított khí-négyzet értéke (Chi-Sq) és a szabadsági fokok száma (DF) is kiszámításra került, ezért csak ellenőrzésképpen kikerestem a khí-négyzet határértéket is a megfelelő táblázatból, amely 9,49. Mivel ez nagyobb, mint a kiszámított khí-négyzet értéke (7,71891), ezért a nullhipotézis elfogadását ez az eredmény is megerősíti.
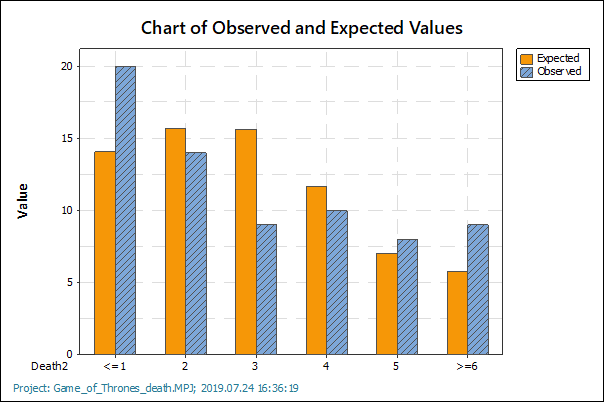
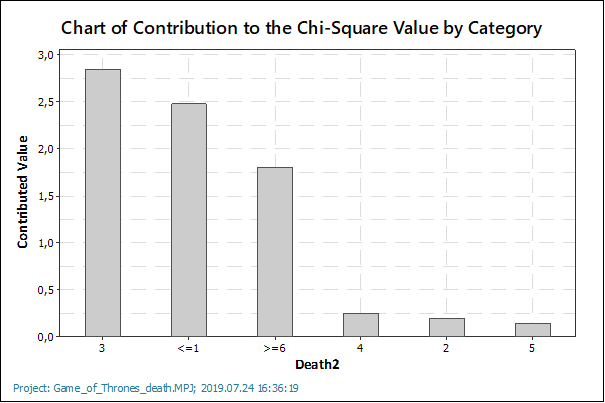
Az illeszkedésvizsgálathoz jár még két diagram is, amelyek segítenek az eredmények elemzésében is. Az egyik beszédesebb (legalábbis a számomra), ez összehasonlítja a valós (Observed) és a várható (Expected) halálesetek számát az összes kategóriára. Ezen jól látható, hogy az első és az utolsó oszlopban van nagyobb eltérés a modell és a valóság között. Ezek azok a kategóriák, amelyeket összevontam, tehát valahol érthető, hogy itt van nagyobb torzulás az eredményekben. Kilóg a sorból még a 3 halálesetet tartalmazó epizódok száma, amelyből lényegesen kevesebb van, mint ami elvárható lett volna.
A másik grafikon egy pareto-diagram, amely azt mutatja be, amely nagyság szerint csökkenő sorrendbe rendezve mutatja be, hogy mely kategóriák járultak hozzá leginkább a modelltől való eltérésekhez. A diagram információtartalma ugyanaz, de másképp olvasható, mint az előző diagram. Egyébként a teszt futtatása előtt beállítható, hogy melyik diagramokat rajzolja meg a program.
Azért, hogy az elemzésünk még cizelláltabb legyen, kiszámítottam az epizódonkénti átlagos 3 haláleset megbízhatósági tartományát, amely azt jelenti, hogy a „végtelen számú” sokaság átlaga valahol ebben a tartományban van, hiszen az adatsorunk tulajdonképpen csak egy minta.
Ezt az intervallumot Minitab-ban a ’Stat’ menü ’Basic Statistics’ almenüjének ’1-sample Poisson rate’ nevű menüpontja segítségével tudjuk kiszámítani.
A menüpontra kattintva ismét megjelenik egy ablak, amelyben be tudjuk állítani a teszt paramétereit. Az ablak baloldalán vannak az adott táblához tartozó mezők nevei találhatók. A jobboldalon fent ki lehet választani, hogy a nyers adatokból vagy összegzett gyakoriságokból szeretnénk dolgozni. Ebben az esetben a nyers adatokkal szeretnék dolgozni ezért a ’One or more samples, each in a column’ pontot választottam.
A ’Sample columns’ mezőben megadható annak az oszlopnak a neve, amelyben a nyers adatok találhatók. Ide a megfelelő oszlop nevét a baloldali listából lehet kiválasztani. A ’Frequency columns (optional)’ mezőt üresen hagytam, mert ide összegzett adatok esetén kell megadni annak az oszlopnak a nevét, amelyben a kategóriánként összegzett gyakoriságok találhatók.
Az eredmény a következő lett:

A ’Total Occurrences’ azt jelenti, hogy összesen 214 haláleset történt a N = 70 epizód alatt- A 95% CI azaz 95% Confidence Interval vagyis a 95%-os megbízhatósági tartomány 1,66124 és 3,49534 között van, tehát a Poisson-eloszlású sokaság átlaga valahol ebben a tartományban van.
Korábban készítettem egy összegzett táblázatot is az illeszkedés vizsgálathoz, amiben összevontam bizonyos kategóriákat, hogy kizárjam a túl alacsony előfordulási gyakoriságokat.
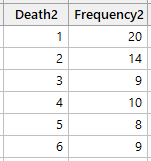
Most kiszámoltatom a Minitab-bal ugyanazt a megbízhatósági tartományt, de az összegzett adatok segítségével. Az adatbeviteli ablakot most a következő módon kell kitölteni:
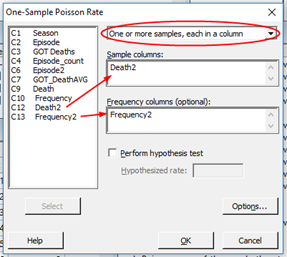
Vigyázat! A jobb felső sarokban ugyanúgy a ’One or more samples, each in a column’ opciót kell kiválasztani, de itt a kategóriák neveit tartalmazó oszlop nevét kell megadni a ’Sample colums’ mezőben, a kategóriák gyakoriságait viszont a ’Frequency columns (optional)’ mezőbe kell kiválasztani. Számomra kicsit fura ez a logika, de így működik a szoftver helyesen. Az ’options…’ nyomógomb segítségével további beállításokat lehet eszközölni.
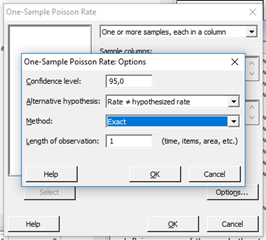
Itt a megbízhatósági szintet lehet beállítani az igényeinknek megfelelően, a hipotézis vizsgálat típusát, úgymint egyoldali vagy kétoldali tesztet akarunk elvégeztetni a szoftverrel, a számítási metódust is ki lehet választani (bár én ezt nem feltétlenül bántanám, mert ez megérne egy újabb cikket), illetve a ’Length of observation’ mezőben be lehet állítani, hogy hány egységre vonatkozzon a vizsgálat. Ez arra jó, hogy ha mondjuk minden évad 10 epizódból állna, akkor egyszerűen tudnánk vizsgálni az évadonkénti átlag megbízhatósági tartományát, elég lenne ide az 1 helyett 10-et írni. A Minitab a következő módon számolja λ és X̅ értékeit:

Összefoglalva: Az elemzés során – számomra meglepő módon – az jött ki, hogy az epizódonkénti halálesetek száma véletlenszerűen változik annak ellenére, hogy nem ezt vártam volna, hiszen nem gondolom, hogy a forgatókönyvírók erre az apróságra tudatosan ügyeltek. Úgy tűnik nem volt semmilyen szándékosság a halálesetek elosztásában az egyes részek között, tök véletlen, hogy így alakult a dolog. Ezzel együtt most ez az elemzés nem volt másra jó, csak arra, hogy bemutassa, hogyan kell megvizsgálni, hogy az adatsorunk Poisson-eloszlású-e vagy sem. De legalább szórakoztató volt az ujjgyakorlat…