Első vendégszerzőm, Dani egy menő konditerem tulajdonosa, de üres óráiban szemmel irányítja a számítógépet. Másik hobbija a gépi tanulás és a digitális képfeldolgozás, szóval nem akármilyen időtöltést választott magának két edzés között. Még nem találkoztunk személyesen, de szenvedélyeinkben egészen egymásra találtunk. Na nem a testedzésben…
Fekete Dániel írása…
Napjainkban egyre többet hallani a gépi tanulás és a mesterséges intelligencia térhódításáról. Lassan nincs olyan területe az életünknek, ahol valamilyen formában nem találkozunk ezen fogalmak valamelyikével, igazából napi szinten részei az életünknek, még ha nem is tudjuk. Bár a sci-fi filmekben a mesterséges intelligencia a jövőben jelenik meg, a valóságban már 1943-ban lefektették a neurális hálózatok elméletének alapjait, 1950-ben megszületett az elnevezés, 1968-ban pedig már az első önvezető autót tesztelte a Continental (további részleteket a következő oldalon találtok).

Fontos megértenünk, hogy a gépi tanulás nem egy kifejezett módszert jelent, hanem módszerek sokaságát, amelyek alapjai legnagyobbrészt a statisztikából jönnek. De hogy mire is alkalmazható a statisztika a gépi tanulásban? Nagyon sok mindenre, például csoportosításra (klaszterezésre) vagy osztályozásra, a szokásos mintázatoktól eltérő esetek kiszűrésére, illetve regresszióelemzések segítségével események bekövetkezésének és jelenségek jövőbeni állapotának becslésére is. Klaszterezés során a célunk, hogy egy adathalmazt csoportokba szedjünk úgy, hogy az egy csoporton belüli elemek hasonlósága a lehető legnagyobb legyen, a csoportok közt viszont a legkisebb, azaz egymástól minél jobban elkülönithető csoportokat kapjunk.
Bár elsőre ez nem tűnhet problémának, de el sem hinnénk hány esetben kell a meglévő adatainkat csoportosítani anélkül hogy tudnánk hogy mi alapján kell azt elvégeznünk. És itt elérkeztünk a gépi tanulás lényegéhez: döntéseket kell hoznunk úgy, hogy döntéseink elvégzésére nincsenek konkrét algoritmusaink (algoritmus = adott probléma megoldásához vezető lépések összessége) csak múltbeli adataink. Ezek az adatok jobb esetben tartoznak valamilyen kategóriához, de gyakran csak az egymáshoz való hasonlóságuk alapján tudjuk besorolni őket.
Hogyan lehet számszerűsíteni két adat hasonlóságának mértékét egy gép számára? Például a távolságuk alapján. Ha most furcsán nézel, hogy hogyan lehet távolságot mérni például az emberek magassága és súlya között, nézd meg ezt a kis ábrát:

Az „A” személy egy 160 cm magas, 50 kilós ember, a „B” pedig 170 cm magas 65 kilós. Vonatkoztassunk el a mértékegységektől és nézzük ezeket a számokat úgy, mint a koordináta rendszerben elfoglalt helyzetet jelentő értékek, vagyis
A(x1 = 160, y1 = 50), B(x2 = 170, y2 = 65)
A köztük lévő távolságot kiszámolni többféle módon is lehet, de a leggyakoribb az Euklidészi-távolság, mely tulajdonképpen annyi, hogy összeadjuk a magasságok és tömegek különbségének négyzetét, majd vesszük ennek az összegnek a négyzetgyökét, azaz esetünkben:
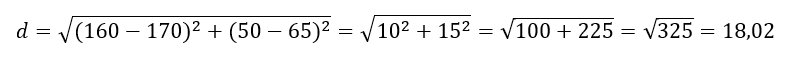
Ha még emlékszel a Pitagorasz-tételre, ott ugyanígy számítható ki a derékszögű háromszög átfogójának hossza a két befogó alapján, csak itt nemcsak két „befogónk lehet, hanem akármennyi! A 18,02-nek nincs mértékegysége, hiszen itt nem almát az almához hasonlítottunk, de ebben nem is ez volt a lényeg, hanem az, hogy ez egy olyan szám, amellyel jellemezni tudjuk két vizsgált dolog többdimenziós távolságát.
Táblázatkezelő programban a következő képletet alkalmazhatjuk a fenti távolság kiszámítására.
=SQRT((x1-x2)^2+(y1-y2)^2)
Ha ábrázolni szeretnénk a magasságoz tartozó súly mellett az életkort is, azt minden további nélkül megtehetjük egy 3 dimenziós koordináta rendszerben. A neheze innentől jön, hiszen van, amikor adatainkat 5, 6 vagy még több dimenzióban kellene ábrázolnunk, ami a technika jelen állása szerint meghaladja a lehetőségeinket. Van rá mód hogy bizonyos dimenzió számot még ábrázoljunk, de számunkra a legfontosabb az, hogy a köztük lévő távolság kiszámolását nem befolyásolja az hogy tudjuk-e ábrázolni vagy sem.
Adatainkat persze nemcsak az adatpontok távolsága alapján csoportosíthatjuk, hanem például az adatpontok sűrűsége alapján vagy bonyolult döntési struktúrák segítségével is, de a cikkünkben bemutatott K-Means klaszterezés pont erre épül.
És hogy miért pont K-Means algoritmus bemutatásával? Ennek több oka is van, de nézzünk meg párat elkezdve az ismerkedést vele:
- ha a gépi tanulásra adjuk a fejünket, ez az egyik első módszer a szakirodalomban
- az egyszerűbb klaszterező algoritmusok közé tartozik
- egyszerűsége ellenére nagyon jó eredményeket lehet elérni vele
- nagyon széles körben felhasználható
A K-means, vagy másnéven k-közép egy centroid alapú klaszterező algoritmus. De mi az a centroid? Egyfajta középpont mely köré az az egyes klaszterekbe tartozó adatok csoportosulnak. A későbbiekben gyakran fogjuk klaszter középpontként is említeni.
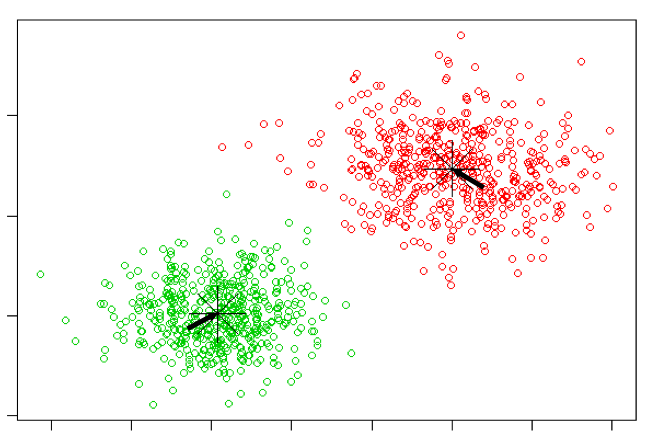
A centroidok segítségével az adathalmazt csoportokra tudjuk osztani anélkül, hogy tudnánk, mi alapján kell a csoportosítást elvégeznünk. A csoportosítás során egyedül az számít, hogy az egyes pontok melyik centroidhoz esnek a legközelebb a fent említett Euklidészi-távolság alapján.
A csoportosítás elvégzéséhez egyetlen paramétert kell előre megadnunk, ez pedig a várható csoportok száma, ennek jelölésére általában a „k” betűt használják. Ha a k-means gyengeségeit kell megemlíteni, az egyik talán az, hogy nem mindig tudjuk előre, hogy az adathalmazból hány csoportot is lehet képezni. Persze van módszer, ami segíthet ennek eldöntésében, de a gyakorlatban inkább csak némi sejtéssel rendelkezünk arról, hogy mi lehet az optimális „k” érték.
A vizsgálat megkezdése előtt nemcsak a csoportok számát, de a centroidok körülbelüli értékét is meg kell adnunk. Ezeket a pontokat teljesen véletlenszerűen választjuk ki az algoritmus indításakor. Az persze segít, ha van valamilyen elképzelésünk a centroidok körülbelüli helyzetéről, mert csökkenti a szükséges iterációk számát.
Első körben kiszámoljuk az adathalmaz minden egyes pontjának távolságát az előre megadott középpontoktól, majd a pontokat elhelyezzük abba a klaszterbe, amelynek a középpontjához az adott pont a legközelebb van. Az egy klaszterbe tartozó pontokat átlagoljuk ezzel kijelölve az új centroid pontokat. Az új centroid pontokhoz viszont újra ki kell számolni a többi pont távolságát, mert előfordulhat, hogy az új centroidokhoz képest a pontok egy részét másik klaszterbe kell áthelyezni. Ez viszont újra megváltoztatja a centroidok helyzetét, és így tovább. Szerencsére néhány ilyen ismétlődő ciklus után már minden pont marad ugyanabban a klaszterben, ahol volt, így megkapjuk a végleges klaszter középpontokat.
Hú, ez így lehet elsőre nem hangzik annyira könnyűnek, de itt egy egyszerű példa mely rögtön bebizonyítja, hogy annyira talán mégsem bonyolult. Bár a példánk túlzottan tökéletes, azaz a valóságban ettől nehezebb problémákba fogunk belefutni, a számolás menete az megegyezik.
Egy x, y koordináta rendszerben megadott adathalmaz esetében legyen az x=1 értékhez tartozó pontok halmaza: 1, 4, 5, 7, 10, 13, 14, 17.
A feltételezésünk az, hogy ezeket a pontokat két csoportra lehet osztani, ezért „k” értéke legyen 2. Válasszuk ki a két kezdeti centroid pontnak a 1-et és a 4-et. Ábrázoljuk adatainkat pontokként a koordináta rendszerben az áttekintés kedvéért, majd kezdjünk hozzá a számolásokhoz. R, Python és egyéb népszerű nyelveken számtalan beépített csomag és kiegészítő van, ami ilyen és ehhez hasonló esetekben megoldja nekünk a számolást, de ez elég egyszerű ahhoz, hogy most megcsináljuk magunk, hiszen az érdekel minket, hogyan működik a módszer.

Írjuk fel egymás mellé a kijelölt pontokat: 1, 4, majd ezek alá számoljuk ki a halmazunk pontjaitól számított négyzetes távolságokat. Az 1 és 1 távolsága (1-1)^2 = 0, az 1 és 4 távolsága pedig (1-4)^2 = 9. Ezzel a módszerrel végig megyünk az összes ponton. Minden ponthoz kapunk két távolságot. Itt nincs más dolgunk, mint csoportosítani a pontokat, mégpedig a legkisebb négyzettávolság alapján. Esetünkben az 1-es pont a 1-es centoridhoz tartozik hiszen hozzá a távolsága 0, a 4-hez viszont 9.
A táblázatomban szürkével jelöltem a legkisebb távolságokat. Ezek alapján megkapjuk az első két klaszterünket. Az új centorid pontokat akkor kapjuk meg ha átlagot számolunk a kapott klaszterek elemeiből. A piros klaszterhez tartozó elem egyelőre csak az 1 melynek átlaga 1, a kék klaszterhez tartozó elemek a 4, 5, 7, 10, 13, 14, 17 melynek átlaga 10.

Ez az átlagnak kapott 1 és a 10 lesz a következő körben használt két centorid pont. Ezekre a klaszter közepekre végig számoljuk újra a távolságokat, és hasonlóképpen csoportosítjuk az elemeket.
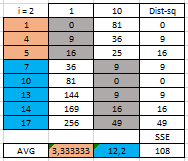
Az egyik új centroidunk 3,33 lett melyhez már a 1, 4, 5 pontok tartoznak, a másik pedig a 12,2 melyhez a 7, 10, 13, 14, 17 pontok tartoznak. A táblázat alatt az SSE (Sum of Squares Error, lásd a Legyenek a négyzetek minél kisebbek…! – útban a lineáris regresszió elemzés felé, című bejegyzést) az adott klaszterbe tartozó pontok négyzetes távolságának összege. Láthatjuk, hogy első körben, a kezdeti centroid pontok mellett ez a szám nagyobb, mint a második körben.
Jöhet a harmadik és a negyedik kör, amit hasonlóan végig számolunk az új kapott centoridokkal:
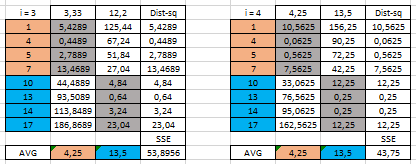
A negyedik körben kapott új centroidok megegyeznek az előzőekkel tehát itt meg is állhatunk.
Ez egy nagyon egyszerű és könnyű feladat volt, ami pont arra elég, hogy némi képet adjon arról, hogy manapság mit értünk gépi tanulás alatt, és mi lehet mögötte. Megjegyzem ezek alapján ne gondoljuk azt hogy a gépi tanulás ennyire egyszerű, hiszen rengeteg összetettebb probléma, és hozzátartozó módszer létezik, de ha eléggé motiváltak és kitartóak vagyunk, akkor meg lehet érteni és tanulni ezeket. A cikk folytatásában a K-Means segítségével egy való életből vett bonyolultabb problémát fogunk hasonlóképpen végig számolni, és részletesebben megnézzük, hogy ezt az egyszerű módszert is milyen komoly feladatok megoldására lehet felhasználni.