

Az R programnyelv és az erre épülő RStudio programozási környezet egy széles körben alkalmazott eszköz statisztikai feladatok elvégzésére. Kicsit részletesebben már írtam róla korábban (Nem muszáj kézzel számolni… - Latin négyzet kísérletterv R-ben). A Six Sigma pedig egy olyan management filozófia, amelyet erősen támaszkodik a különféle statisztikai módszerek alkalmazására főleg műszaki (de nem kizárólag műszaki) jellegű problémák megoldására és a folyamatok optimalizálására. Erről röviden már írtam (Six Sigma és költségcsökkentés), de sok egyéb általános ismertető anyag fellelhető a weben.
A Six Sigma alapvetően nem a kisvállalkozások játszótere, mert a főleg a képzés és az alkalmazott statisztikai programok költségesek, ezért kevés kis cég dönt úgy, hogy belevág a Six Sigma filozófia bevezetésébe. Pedig miért ne lehetne egy kis cégnél is alkalmazni a statisztikai eszközöket műszaki problémák megoldására és a költségek csökkentésére. Persze kell hozzá tulajdonosi hit és akarat, de a világ már sokszorosan bebizonyította, hogy a tényadatok célirányos feldolgozása és az objektív tények alapján történő döntéshozatal pénzben mérhető versenyelőnyt jelent a vállalkozások számára. Persze nem szükséges a Six Sigma filozófia összes elemét mindenképpen alkalmazni, a fontos az, hogy higgyünk a számok erejében („Ha a japánok tudják, mi miért nem?” – W. Edward Deming igaz története).
Ma már nem lehetetlen a Six Sigma statisztikai eszközeinek elsajátítása, rengeteg cikk és videó található meg a neten, többek között ezen a blogon is leginkább azok a módszerek kerültek ismertetésre, amelyeket leggyakrabban szoktunk alkalmazni a Six Sigma projektek során. A szoftver kérdése most már szintén nem megoldhatatlan probléma, hiszen a Minitab-bal, illetve a hasonló költséges statisztikai programokkal szemben például az R vagy a Python teljesen ingyenesen használható szoftverek. Ezek is képesek bármit elvégezni, amit például a Minitab, csak persze egy kicsit másképpen.
Nekem egy kicsit az a benyomásom, hogy a Minitab a statisztikai szoftverek Apple-je, az R pedig az Android. De nem a mai Android, hanem még az, amelyiket nem uralta le a Google. Szóval a Minitab egy nagyon struktúrált, nagyon összeszedett rendszer, ahol a felhasználók lehetőségei erősen korlátozottak. Ezért cserébe kapsz egy könnyen és gyorsan kezelhető, egyszerűen paraméterezhető rendszert, amelyet könnyű megtanulni és némi háttérismerettel és gyakorlattal könnyű is használni.
Ezzel szemben az R-ben is minden megvan, ami kell, de keresgélni és kutatni kell, egy adott eszközt nem mindig ott találsz meg, ahol várnád és a legváratlanabb helyekről bukkannak elő hasznos holmik. Küszködni kell a függvények paraméterezésével és az eredmény nem mindig az elsőre, amit látni szeretnénk. Ezért persze cserébe egy sokkal rugalmasabb és testre szabhatóbb rendszert kapunk. És persze ingyen…
A felvezetés egy kicsit hosszadalmasra sikeredett, de végre eljutottam a tényleges mondanivalómhoz. Az R-t tényleg nagyon sok helyen alkalmazzák a gyakorlatban, de a Six Sigma a többihez képest egy kicsit elhanyagolt területnek tűnik. Nem mondom, hogy nincsenek olyan elemkönyvtárak, amelyek a Six Sigmával foglalkoznának, meg könyvek, amik a Six Sigma R-beli alkalmazásáról szólnak, de akármennyit is böngésztem a weben, nem találtam egy olyan jól összeszedett összefoglalót, amely tényleg átfogóan tárgyalná a Six Sigma eszköztár gyakorlati alkalmazását R-ben. Emiatt született meg az elhatározás, hogy indítok egy sorozatot „Six Sigma in R” címmel, amelyben szépen, lépésenként végigveszem a Six Sigma fontosabb statisztikai eszközeinek alkalmazását. Ez a cikk az első a sorban, amelyben a leíró statisztikák alkalmazásáról lesz szó.
Ha sikerült felkeltenem az érdeklődésed az R és az RStudio iránt, akkor szeretném a figyelmedbe ajánlani a következő segédletet:
https://psycho.unideb.hu/munkatarsak/abari_kalman/szamitastechnika_II/
bevezetes_az_R_be_2008_04.pdf
Én ezzel a relatíve rövid és a kezdők számára nagyon jól felépített segédlettel kezdtem az ismerkedést az R-rel. Állítom, hogy ebből az anyagból tanultam a legtöbbet, és mivel tényleg a legalapabb alapoktól kezdi el a programnyelv bemutatását a könyv, ezért olyanok számára is jó lehet, akik nem foglalkoztak még programozással. Hálás köszönet érte a szerzőnek…
Szóval vágjunk bele…
A leíró statisztikai eszközök bemutatásához az R egyik beépített adatsorát fogom alkalmazni. Szerencsére egész sok ilyen minta adatsort találunk R-ben, amelyeket gyakorlásra és tanulásra tudunk alkalmazni. Sajnos ezeknek nem találtam még olyan komplett gyűjteményét, amely témakörök, vagy az alkalmazható eszközök alapján kereshetően tartalmazná ezeket. A legteljesebb ilyen gyűjtemény a következő linken található:
https://vincentarelbundock.github.io/Rdatasets/datasets.html
Vannak olyan mintaadatok, amelyek az R alapváltozatában is benne vannak, másokat egy-egy függvénygyűjtemény (library) betöltésével kapunk meg.
A hatalmas választékból csak úgy találomra egy olyat választottam, amely nagyjából alkalmas arra, hogy bemutassam a leíró statisztikák alkalmazását. Ez a ChickWeight nevű adatsor, amely – állítólag – egy olyan kísérlet eredménye, ahol azt vizsgálták, hogy a csirkéknek hogyan nő a tömege az életkor előrehaladtával, ha különféle tápokkal etetjük őket. Az adatsor betöltéséhez elég, ha beírjuk a nevét a Console-ba vagy egy R szkript első sorába és a CTRL-Enter megnyomásával már be is töltődik az adatsor.
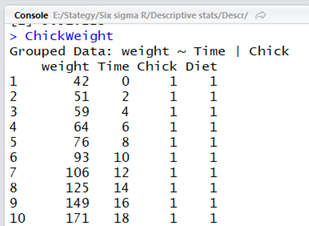
Az egyes oszlopokra úgy hivatkozhatunk, hogy az adattábla neve után teszünk egy $-jelet és ezután adjuk meg a megfelelő oszlop nevét.
Megfigyelhető, hogy a ’weight’ oszlop neve kisbetűvel, a ’Time’ oszlop neve viszont nagybetűvel kezdődik. Sajnos az R érzékeny a kis-, és nagybetűk használatára, így ha azt írnánk véletlenül, hogy ’ChickWeight$Weight’, vagy ’chickweight$weight’, akkor a program hibaüzenettel tér vissza.
R-ben a leíró statisztikák alkalmazása elsőre nem bonyolult. Van egy csomó olyan függvény, amelyek segítségével egyenként ki tudjuk számolni egy adatsor átlagát, mediánját, szórását, és egyéb más jellemzőit. Ha például beírjuk azt, hogy mean(ChickWeight$weight), akkor a következőt kapjuk:
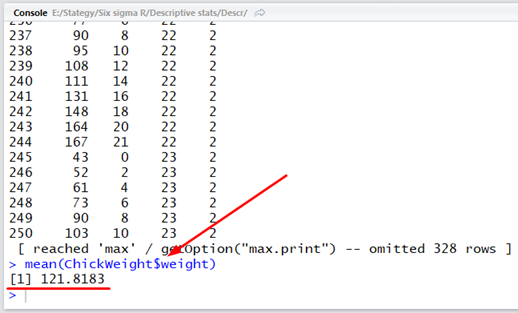
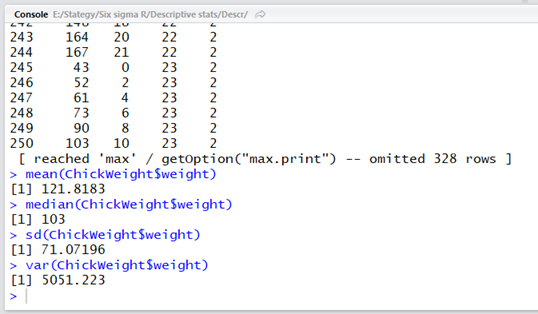
Hasonlóképpen, ha a ’weight’ oszlop mediánjára, szórására vagy varianciájára vagyunk kíváncsiak, akkor azt is megkaphatjuk:
Az átlag standard hibájához viszont már számolgatnunk kell:
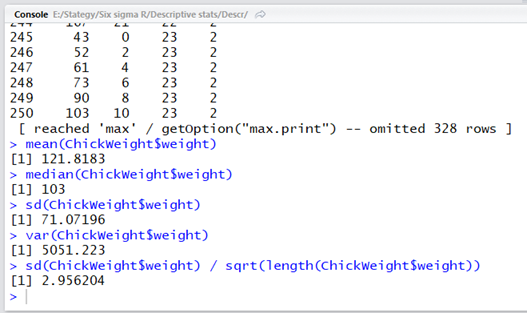
Az sd() függvény a szórásra vonatkozik a ’standard deviation’ kifejezés után, a var() függvény pedig a varianciát jelenti a ’variance’ kifejezésről elnevezve. Az sqrt() függvény a négyzetgyökvonás függvénye a táblázatkezelőkhöz hasonlóan (’square root’). Az átlag standard hibáját se-vel jelöljük, és részletesebben egy korábbi videóban beszéltem róla (Az átlag standard hibája)
Említést érdemelnek még a quartilisek (Quartilisek – szeleteljük fel az adatsort!), amiket a quantile() függvénnyel tudunk lekérdezni.

A függvény argumentumai között szereplő ’probs = ’ paraméterrel (gondolom a ’probabilities’ szó rövidítése) tudjuk megadni, hogy melyik kvartiliseket szeretnénk látni. A c() függvény segítségével egyedi listákat lehet létrehozni az R-ben, jelen esetben a lista azokat a százalékos értékeket tartalmazza, amelyeknél lévő értékekre kíváncsiak vagyunk.
Azonban ezt egy táblázatkezelő is ugyanígy tudja, ehhez teljesen felesleges egy plusz szoftvert feltelepíteni a számítógépre, annak megtanulásáról nem is beszélve. Amit én keresek, az egy olyan összefoglaló, ami úgymond egy gombnyomásra kiadja azokat a legfontosabb leíró statisztikákat egy adatsoról, amikre az esetek 90%-ában kíváncsi lehetek. Ilyen összefoglaló lekérdezések is vannak az R alapcsomagjában, de nekem nem igazán szimpatikusak, mert mindegyikből hiányzik valami. Olyan lekérdezés, amelynek a formátumát megszoktam és amely számomra azt az összefoglalást nyújtja, amelyet már megszoktam, a ’psych’ nevű függvénykönyvtárban található. Ehhez viszont telepítenünk kell ezt a függvény gyűjteményt, amelyet vagy az RStudio jobb alsó ablakában a ’Packages’ fülön tudunk tudunk megtenni, vagy a fentiekhez hasonlóan parancssorból. az ’install.packages(„psych”) parancs begépelésével tudjuk elvégezni. Ekkor az R a CRAN szerveréről (amely olyasmi, mint a Play Áruház az Androidon) letölti a szükséges file-okat és telepíti a csomagot. Ezt elvileg csak egyszer kell megtenni, utána már csak be kell tölteni az éppen szükséges függvény könyvtárat, amikor éppen használni akarjuk.
A csomag betöltése a ’library(psych)’ paranccsal lehetséges. Azt csak a jóisten tudná megmondani, hogy az ’install.packages()’ esetében miért kell a csomag nevét idézőjelbe tenni, a ’library()’ esetében pedig miért nem, de ez mindegy is, első a szintaxis!

A ’psych’ csomagon belül van egy ’describe()’ nevű függvény, amellyel egy a Minitab-éhoz hasonló leíró statisztikai összefoglalót lehet lekérni egy adatsorról. Az előbbi példánál maradva ez a következőképpen néz ki:
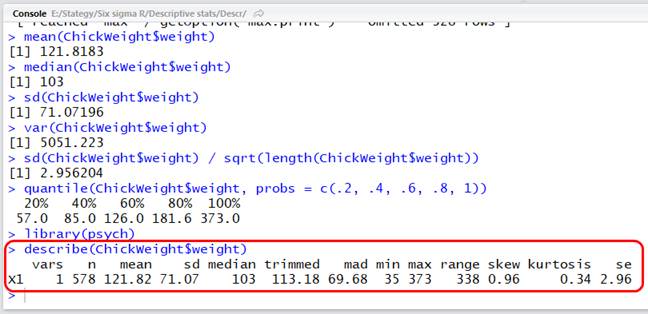
A kapott eredmény tartalma a következő:

A ’describe()’ függvénynek van jónéhány hasznos paraméterezési lehetősége. Be lehet állítani, hogy tegye bele a riportba, hogy hány nem érvényes elem van az adatsorban, legyen-e benne a dőlés (skewness) és a lapultság (kurtosis). Például, ha nem szeretnénk a dőlést és a lapultságot látni, viszont ezek helyett a quartiliseket és a Q3 – Q1 különbségét (Interquartile range = IQR) szeretnénk megjeleníteni, akkor a következő paraméterek alkalmazásával átalakíthatjuk a jelentést:
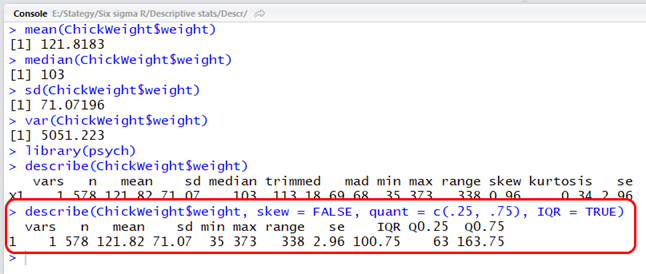
A források között található egy olyan oldal, ahol a ’describe()’ függvény paraméterezési lehetőségei részletesen le vannak írva.
Előfordulhat, hogy az adataink valamilyen szempont szerint csoportosítva vannak, és szeretnénk az eredményeket csoportonkénti bontásban látni, akkor ezt a ’describeBy()’ függvény segítségével tehetjük meg.

A ’group = ChickenWeight$Diet’ paraméter megadásával tudtam beállítani, hogy a csirkék tömegét a különféle étkezési módok alapján külön-külön listázza ki a jelentés. A ’describeBy()’ függvény ugyanúgy paraméterezhető, mint a ’describe()’ függvény.

Ha viszont arra lennék kíváncsi, hogy a csirkék tömege hogyan változik a táplálkozási mód ÉS az életkor függvényében, akkor a ’describeBy()’ függvényt másképpen kell meghívni. A ’group =’ paraméternek csak egy értéke lehet, itt a fenti tömbösített értékadás nem működik. Ha viszont a következő módon hívom meg a függvényt, akkor már igen.
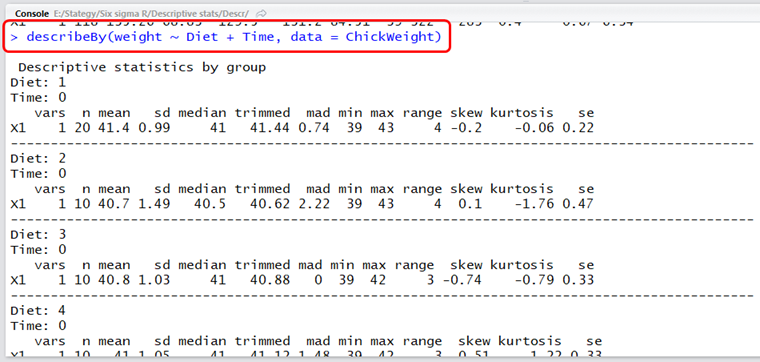
A zárójelben található ~ azt jelenti, hogy „valaminek a függvényében”, vagyis a függvény úgy értelmezze a peramétert, hogy a csirkék tömegét (weight) az étrend (Diet) és az életkor (Time) függvényében listázza ki. Hogy teljes legyen a káosz, ugyanezt úgy is el lehet érni, hogy
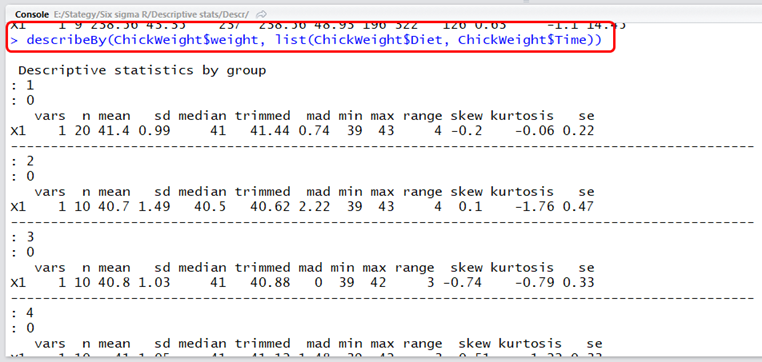
Ily módon valószínűleg 3 és még több paraméter szerint is szét lehet bontani az adatokat. Az pedig kinek-kinek az ízlésére van bízva, hogy melyik paraméterezési eljárás szimpatikus a számára.
Végezetül érdekességképpen itt egy másik leíró statisztika, ezúttal az FSA csomagból. Ez a ’summarize()’ függvény. A történet pikantériáját számomra az adja, hogy az FSA csomag a „Fischeries Stock Assessment” becsületes névre hallgat, és a szerzője, Derek H. Ogle kifejezetten a halállomány felmérésére szolgáló statisztikák miatt írta. Ez is mutatja, hogy mennyire sok területen használják az R-t. A ’summarize()’ függvény nagyon hasonlóan működik a ’describe()’ függvényhez, így ennek részleteibe most nem mennék bele.
Ha esetleg ismersz még más hasznos leíró statisztikai eszközöket, akkor kérlek, oszd meg kommentben!
FRISSÍTÉS 2021.02.26:
Közben találtam egy nagyon érdekes lehetőséget az adatok gyors áttekintésére, amely főleg akkor jó, ha az adattáblánk sok sorból áll. A függvény bemutatására készítettem egy kis adattáblázatot:
minta1 <- rnorm(50, mean = 0, sd = 1)
minta2 <- rnorm(50, mean = 0, sd = 1.1)
minta3 <- rnorm(50, mean = 0, sd = 3)
mintak <- data.frame(minta1, minta2, minta3)
Ez a kis kódrészlet létrehozott egy adattáblát, amely három oszlopból áll. Mindhárom oszlop egy véletlenszerűen létrehozott 50 elemből álló normál eloszlású minta. A célunk csak annyi, hogy ha például most látnánk először ezt az adattáblát, akkor egyetlen függvény segítségével kaphatunk egy áttekintést az adatokról.
library(skimr)
skim(mintak)
A parancs hatására a következő eredményt kapjuk.
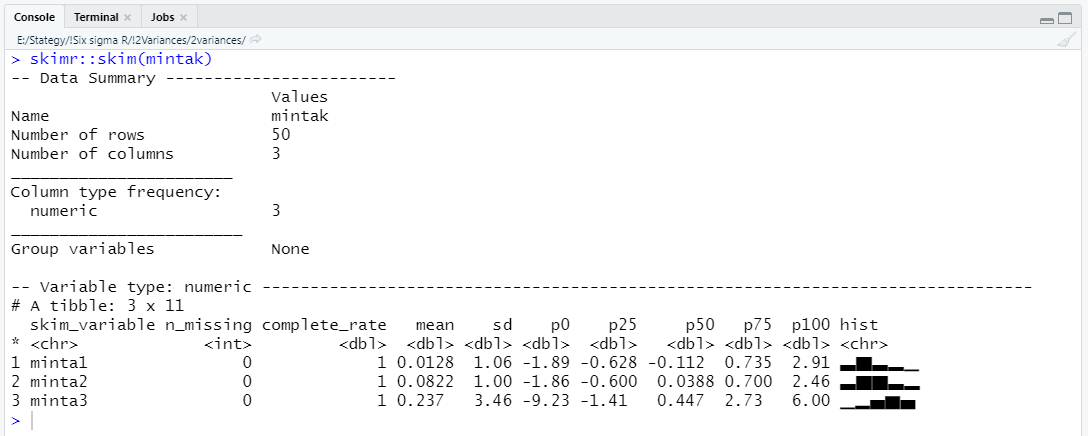
Ez egy szépen rendezett összefoglaló az adattábláról és a benne lévő oszlopokról is. Biztosan lehetne több dolgot is megjeleníteni, de szerintem ez egy jól használható függvény arra, hogy kapjunk egy első benyomást az adatokról.
Források:
Emilio L. Cano, Javier M. Moguerza, Andrés Redchuk: Six Sigma with R, Statistical Engineering for Process Improvement, Springer
Basic descriptive statistics useful for psychometrics
https://personality-project.org/r/html/describe.html
Webinar: Tidyverse Exploratory Analysis (Emily Robinson) - YouTube
Link




