

Adatsorok elemzése során gyakran ütközünk bele olyan adatpontokba, amelyek nem illenek bele a többi pont által kialakított mintázatba. Ezeket a pontokat általában nem kedveli senki, mert elrontják az egyébként tökéletesnek látszó képet. Egy kieső érték több szempontból is bosszantó lehet:
- Egyrészt egy látszólag kieső értékről nem tudhatjuk biztosan, hogy az tényleg kieső érték,
- A kieső érték jelenléte azt jelzi, hogy az adatok alapján kialakított elméleti modellünk nem írja le elég jól a valóságot, illetve
- döntést kell hoznunk arról, hogy a kieső értéket figyelembe vesszük az elemzés során vagy nem.
Mit kezdjünk ezekkel a pontokkal? Töröljük őket vagy megtartsuk? Ez nem is olyan egyszerű döntés...
Amikor kieső értékek zavarnak meg egy egyébként tökéletesnek látszó gyakorisági eloszlást, azt „szennyezett” eloszlásnak (contaminated distribution) nevezzük. Ennek egy klasszikus példája az, amikor a II. Világháború idején az amerikai haditengerészet kifejlesztett egy új típusú optikai távolságmérő berendezést, amely azon az elven a működött, hogy a felhasználónak egy nagy háromszöggel ki kellett jelölnie a célpont háromdimenziós sztereoszkópikus képét a kijelzőn. Egy vizsgálat során több száz tengerész bevonásával próbálták a tudósok meghatározni a berendezés statisztikai hibáját. A tengerészeknek meg kellett határozniuk egy ismert távolságra lévő célpont távolságát. Az eredmények egészen meglepőek voltak, ugyanis a távolságmérési hibák eloszlása nem normál eloszlást követett, hanem egyfajta szabálytalan eloszlást. A kutatók végül arra jöttek rá, hogy a vizsgálatban részt vevő tengerészek egy részének kisebb-nagyobb mértékű szemtengelyferdülése volt, amely együtt jár a nem megfelelő térlátással. Ha a tudósok figyelmen kívül hagyták volna a zavaró adatpontokat és nem járnak utána ezek okainak, sohasem jöttek volna rá, hogy a berendezést a tengerészek egy része nem tudja megfelelően alkalmazni.
/forrás: David Salzburg: The lady tasting tea, Henry Holt and Company LLC, 2002/
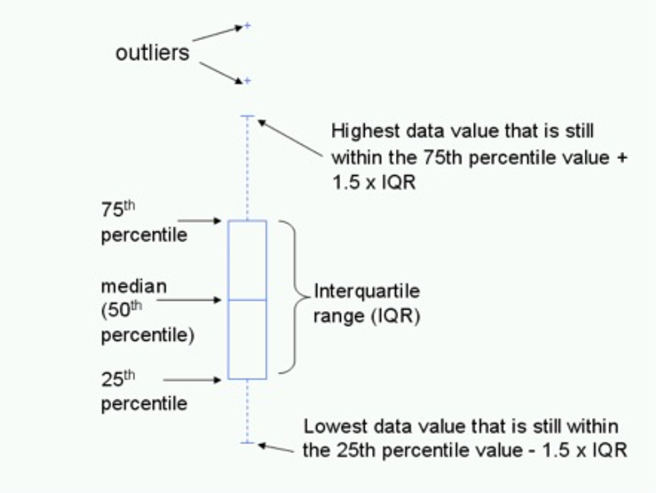
Visszatérve a kieső értékek elemzéséhez, az első probléma tehát az, hogy mikor tekinthetünk egy pontot kieső értéknek. Erre többféle teszt is létezik. Az egyik legegyszerűbb megközelítés a quartilisek alapján (Quartilisek – szeleteljük fel az adatsort!) számítja ki azt a határértéket, amely alapján eldönthető, hogy a pont vagy pontok kieső értékek-e. Amint azt a lenti ábra is mutatja, ezt az úgynevezett box-plot diagramok esetében alkalmazzuk és nagyon könnyen kiszámítható a quartilisek segítségével. Ha az adathalmaz pontjait négy egyenlő részre bontjuk a korábban hivatkozott bejegyzésben foglaltak szerint, akkor a Q3 és a Q1 quartilisek különbsége az úgynevezett interkvartilis tartomány (interquartile range). Ha ennek a tartománynak a másfélszeresét kivonjuk a Q1-ből, illetve hozzáadjuk a Q3-hoz, akkor megkapjuk azt az alsó és felső határt, amelyen kívül lévő pontokat kieső értéknek tekintjük.
Amikor bizonyítottan normál eloszlású adatokkal dolgozunk, akkor több további lehetőségük is van a kieső értékek azonosítására. Hatékony lehet például a Z-érték (Első az egyenlők között - a standard normál eloszlás) kiszámítása a korábbi cikkből már jól ismert képlettel:
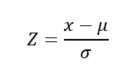
Z értéke megadja, hogy az adott x-el jelölt pont milyen messze van az átlagtól. A normál eloszlás már korábban megismert tulajdonságai alapján (Ismerd meg a hibafüggvényt! – A normál eloszlás legfontosabb tulajdonságai) feltételezhetjük, hogy ha a fenti képlettel kapott Z-érték jelentősen kisebb, mint -3 vagy jelentősen nagyobb, mint +3, akkor nagy valószínűséggel kieső értékkel van dolgunk.
Ezek azonban nem valódi hipotézis vizsgálatok, vagyis nem egyértelműen bizonyítják, hogy egy pont kieső érték, avagy sem. Normál eloszlású adatok esetében van még két elterjedt teszt, amelyet gyakran alkalmaznak a gyakorlatban. Az egyik a Grubb’s test for outliers, a másik pedig a Dixon’s Q-test.
A Grubb’s outlier tesztet Frank E. Grubb’s publikálta 1950-ben. Ez egy hipotézisvizsgálat, amely tulajdonképpen csak arra az egy kérdésre válaszol, hogy van-e kieső érték az adathalmazban, vagy sem. A nullhipotézis az, hogy az adathalmazban van kieső érték, az ellenhipotézis pedig az, hogy nincs. A teszt lényege az, hogy az adathalmaznak azt a pontját vizsgáljuk, amelyik a legtávolabb van az adathalmaz átlagától. A próbastatisztika tulajdonképpen annyi, hogy az előző bekezdésben leírtaknak megfelelően kiszámoljuk a ponthoz tartozó Z-értéket. Mivel ez is egy hipotézis-vizsgálat, ezért itt is van egy kritikus határérték. Ami érdekes, hogy ez esetben nem standard normál eloszlást, hanem t-eloszlást használunk a kritikus érték meghatározására, mert itt sem a sokaság, hanem a minta szórásával számolunk. Ennek a tesztnek az esetében arra kell ügyelnünk, hogy csak egyetlen kieső pont tesztelésére alkalmas, nem szabad ismételten alkalmazni úgy, hogy az előző teszt során azonosított kieső értéket eltávolítjuk az adathalmazból. Ennek az oka elég egyszerű: ha az adathalmazból kivesszük a kérdéses kieső értéket, akkor már egy másik adatsort fogunk kapni, amelynek más az átlaga és a szórása, azaz az ismételt teszt során azonosított kieső érték ugyan kieső értéke lesz az új adatsornak, de semmit sem fogunk tudni arról, hogy vajon kieső érték lett volna az eredeti adatsor esetében, vagy sem.
A Dixon’s Q-test hasonlóképpen hipotézisvizsgálat, mint a Grubb’s teszt, és az előfeltétele is hasonlóképpen az, hogy a vizsgált adathalmaznak normál eloszlásúnak kell lennie és szintén nem szabad szekvenciálisan ismételve alkalmazni. A Dixon’s Q-test előnye a Grubb’s teszttel szemben az, hogy egy kicsivel többféle esetet is tud kezelni. Amíg a Grubb’s teszt nem képes alkalmazkodni az adathalmaz többi pontjának elhelyezkedéséhez, addig a Q-teszt hatféle különböző esetet is le tud kezelni, amelyek a következőképpen néznek ki:
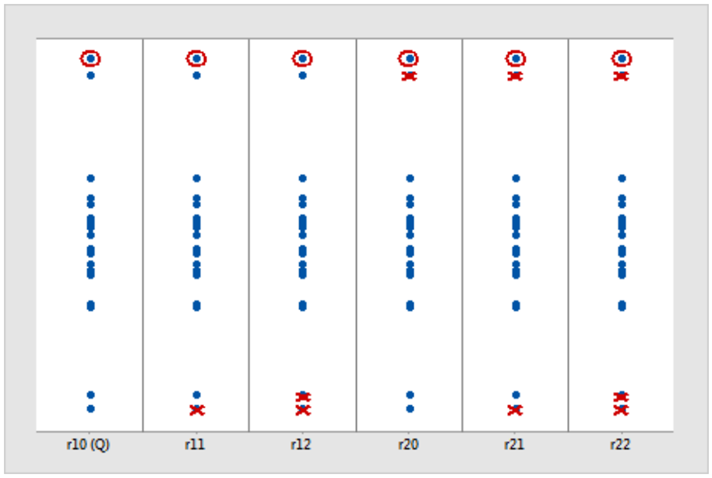
A korábbiakhoz hasonlóan itt is az adathalmaz legtávolabbi pontját vizsgáljuk, de ha több potenciális kieső érték is van az adathalmazban, úgy a zavaró kieső értékeket „ki tudjuk maszkoni” a megfelelő teszt alkalmazásával. A fenti ábrán a bekarikázott pontok jelzik azt az értéket, amelyet vizsgálunk, a piros kereszttel áthúzott pontok pedig azokat a pontokat, amelyeket kizárunk a vizsgálatból az adott teszt során.
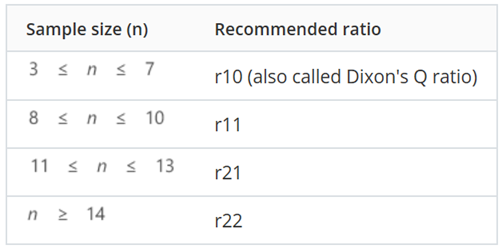
További segítség lehet a megfelelő teszt kiválasztásához az adathalmaz elemeinek száma. Mivel Dixon azt feltételezte, hogy egy nagyobb elemszámú mintában több kieső érték lehetséges, ezért adott egy iránymutatást arra vonatkozóan is, hogy a vizsgált minta elemszámától függően melyik tesztet érdemes alkalmazni.
A próbastatisztika lényege tulajdonképpen annyi, hogy a vizsgált legszélső pontnak a hozzá legközelebb álló ponttól való abszolút távolságát hasonlítja össze a teljes adathalmaz terjedelmével, azaz a legnagyobb és a legkisebb adatpont távolságával. A próbastatisztika kiszámításához használandó képletek a következőképpen néznek ki:

Az így kapott próbastatisztika értékét a Q-krit értékek táblázatával kell összehasonlítani (egy ilyen táblázatot itt találsz: http://webspace.ship.edu/pgmarr/Geo441/Tables/Dixon%20Table,%20Expanded.pdf)
Ha a próbastatisztikai értéke kisebb, mint a táblázatból kikeresett kritikus érték, akkor elfogadjuk a nullhipotézist, vagyis a vizsgált pont nem kieső érték. Ellenkező esetben viszont elutasítjuk a nullhipozézist, és az ellenhipotézist fogadjuk el, azaz a vizsgált pont kieső érték.
Mindkét teszt annyira egyszerű, hogy lényegük kivételesen a wikipédián található leírásokból is jól megérthetők.
Léteznek még komplex grafikai módszerek a kieső értékek azonosítására, mint például a Dbscan (Density Based Spatial Clustering of Applications with Noise), illetve az Isolation Forests.
Források:
A brief overview of outlier detection techniques
https://towardsdatascience.com/a-brief-overview-of-outlier-detection-techniques-1e0b2c19e561
Wikipédia – Grubb’s test for outliers
https://en.wikipedia.org/wiki/Grubbs%27s_test_for_outliers
Wikipédia – Dixon’s Q-test
https://en.wikipedia.org/wiki/Dixon%27s_Q_test
Sebastian Raschka: Dixon’s Q test for outlier identification – A questionnable practice, Jul 18, 2014
https://sebastianraschka.com/Articles/2014_dixon_test.html





